课程
-
第十一章 微服务 Mon May 30 2022 19:31:05 GMT+0800 (中国标准时间) [中间件技术 2022春]
-
第九章 池化和负载均衡中间件 Mon May 30 2022 19:30:45 GMT+0800 (中国标准时间) [中间件技术 2022春]
-
期末说明2022 Sun May 29 2022 16:47:15 GMT+0800 (中国标准时间) [中间件技术 2022春]
-
第十一章微服务架构 Sun May 22 2022 06:54:19 GMT+0800 (中国标准时间) [中间件技术 2022春]
-
实验六:Web服务调用(选做) Sun May 22 2022 06:43:25 GMT+0800 (中国标准时间) [中间件技术 2022春]
-
第十章 Web服务 Sun May 22 2022 06:40:46 GMT+0800 (中国标准时间) [中间件技术 2022春]
-
第九章 事务处理中间件 Sun May 22 2022 06:39:08 GMT+0800 (中国标准时间) [中间件技术 2022春]
-
实验五:数据处理中间件(选做) Sun May 08 2022 17:12:23 GMT+0800 (中国标准时间) [中间件技术 2022春]
-
第八章 数据存取中间件 Mon Apr 25 2022 10:45:03 GMT+0800 (中国标准时间) [中间件技术 2022春]
-
第七章 消息中间件 示例代码 Mon Apr 25 2022 10:44:00 GMT+0800 (中国标准时间) [中间件技术 2022春]
-
第七章 消息中间件 Mon Apr 25 2022 10:43:34 GMT+0800 (中国标准时间) [中间件技术 2022春]





新闻
MOCOM实验室长期招募研究生/本科生 2018-11-29
赖永炫老师接受中国纪检监察报专访 Tue Sep 15 2020 11:03:37 GMT+0800 (中国标准时间)
实验室团队获得”北京科技战疫·大数据挑战赛”二等奖 Thu Jul 30 2020 18:01:17 GMT+0800 (中国标准时间)
赖永炫老师获得2019年度CSC-IBM中国优秀教师奖教金 Fri May 22 2020 19:51:03 GMT+0800 (中国标准时间)
YOCSEF厦门论坛举行“毕业论文查重”主题辩论 Mon Jul 22 2019 15:01:27 GMT+0800 (中国标准时间)
麦考瑞大学刘冠峰博士访问实验室 Sat Jun 22 2019 23:35:50 GMT+0800 (中国标准时间)
讲座通知:社交网络环境中的可信计算 Sat Jun 15 2019 17:08:48 GMT+0800 (中国标准时间)
项目
Xiamen Taxi Dataset Wed Apr 01 2020 15:42:07 GMT+0800 (中国标准时间)
The Xiamen taxi trajectory datasets consist one-month trajectory data of almost 5,000 taxicabs in Xiamen, totally about 220 million GPS position records and 8 million live trips. On the time aspect, the dataset covered all the daytime and nighttime on both weekdays and weekends, being able to reflect mobility patterns in heavy, moderate, and light traffic conditions. Paper about a taxi route recommendation systems:
Yongxuan Lai, Zheng Lv, Kuan-Ching Li, Minghong Liao: Urban Traffic Coulomb's Law: A New Approach for Taxi Route Recommendation, in IEEE Transactions on Intelligent Transportation Systems, Volume 20, Issue 8, Aug. 2019, Pages 3024-3037. [PDF]
Zheng Lv, Yongxuan Lai, Kuan-Ching Li,Minghong Liao and Xing Gao: Taxi Route Recommendation Based on Urban Traffic Coulomb's Law, the 18th International Conference on Web Information Systems Engineering (WISE), 2017
Visualization
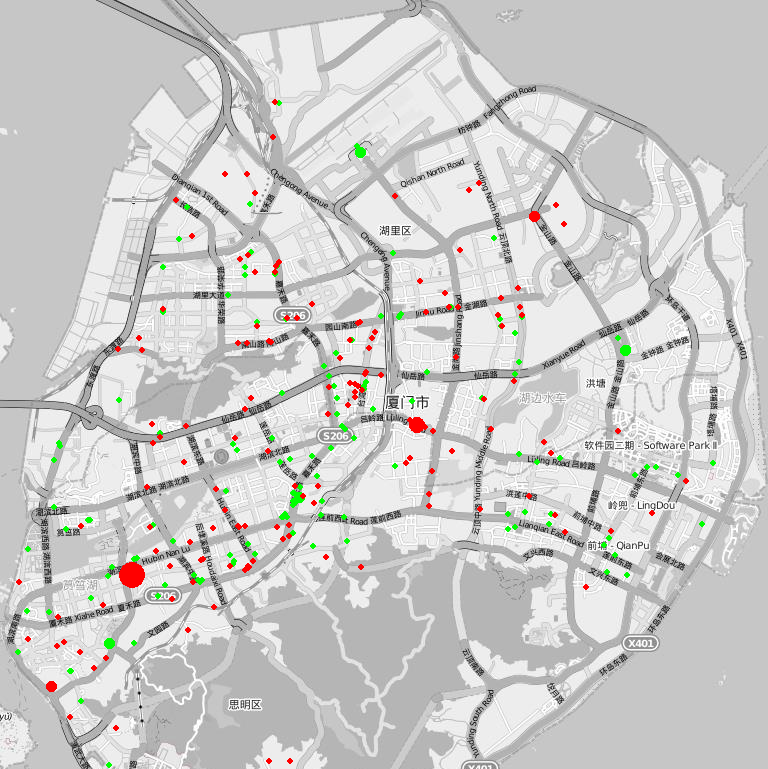
The total trip happend from 07:00 a.m. to 08:00 a.m. on July 24th, 2017 (green spot stands for the start location of a trip and red spot stands for the end location of a trip).
Description
The form of the position trajectories is ".dmp" and can be imported into Oracle. The files consist of multiple serialized data units of the following structure, and each data unit is a sample of a taxi's location and time.
The form of the operation trajectories is ".mdf" and can be imported into SQL Server. The files consist of multiple serialized data units of the following structure, and each data unit is a sample of a taxi's trip.
Data Structure
position trajectories
typedef struct _pdata_unit{
char CLBH; // Car ID (e.g. 3459271471)
datetime GPSTIME; // GPS time (e.g. 2014-07-02 15:31:34)
double JD; // Location Longitude (e.g. 24.4752283333333)
double WD; // Location Latitude (e.g. 118.024231666667)
int GD; // Orientation(Orientation/10, bettwen 0 to 35)
char SUDU; // Speed (km/h)
char JQBH; // alarm information (including the information on whether the taxi is occupied or not)
} data_unit;
operation trajectories
typedef struct _odata_unit{
char SIM; // Car ID (there is a one-to-one correspondence betwwen _pdata_unit.CLBH and _odata_unit.SIM)
int GPSONTIME; // GPS time when the trip start (e.g. 2014-07-01 00:01:17.000)
int GPSONTIME; // GPS time when the trip end (e.g. 2014-07-01 00:01:53.000)
char SJD; // Longitude when the trip start (Longitude*10e6, e.g. 118122895)
char SWD; // Latitude when the trip start (Latitude*10e6, e.g. 24483057)
char SANGLE; // Orientation when the trip start (Orientation/10, bettwen 0 to 35)
char EJD; // Longitude when the trip end (Longitude*10e6, e.g. 118122895)
char EWD; // Latitude when the trip end (Latitude*10e6, e.g. 24483057)
char EANGLE; // Orientation when the trip end (Orientation/10, bettwen 0 to 35)
double DISTANCE; // driving distance of this trip (e.g. 0.2km)
double MONEY; // income of this trip (e.g. 9.6)
} data_unit;
You are welcome to contact: laiyx@xmu.edu.cn.
更多
XMU IOV Simulator Sat Oct 20 2018 11:34:54 GMT+0800 (中国标准时间)
1 总体介绍
随着汽车技术的发展,车辆数量迅速增长,交通状况日益恶化,为加强车辆之间的信息交互,减少车辆事故,车联网(IOV)的概念应运而生。XMU IOV Simulator是一个高效的模拟器,以模拟IOV节点的移动性和应用。
车联网模拟器的主要设计思路如下:
- 三层模型,将网络分为三层,分别是车辆节点,雾节点和云节点。 具有计算能力的雾节点可以与车辆节点和云节点通信,可以减轻云节点的压力;车辆与雾节点的通信相当于车联网中V2I的形式。
- 包括流量模拟器和网络模拟器功能:两个子系统的紧密耦合有助于及时进行交互和反馈,提高系统性能。仿真器可以导入和显示不同的城市地图,并根据不同的路由协议和调度算法对车辆的机动性进行仿真和可视化,

图1 基于雾节点的车联网示意图
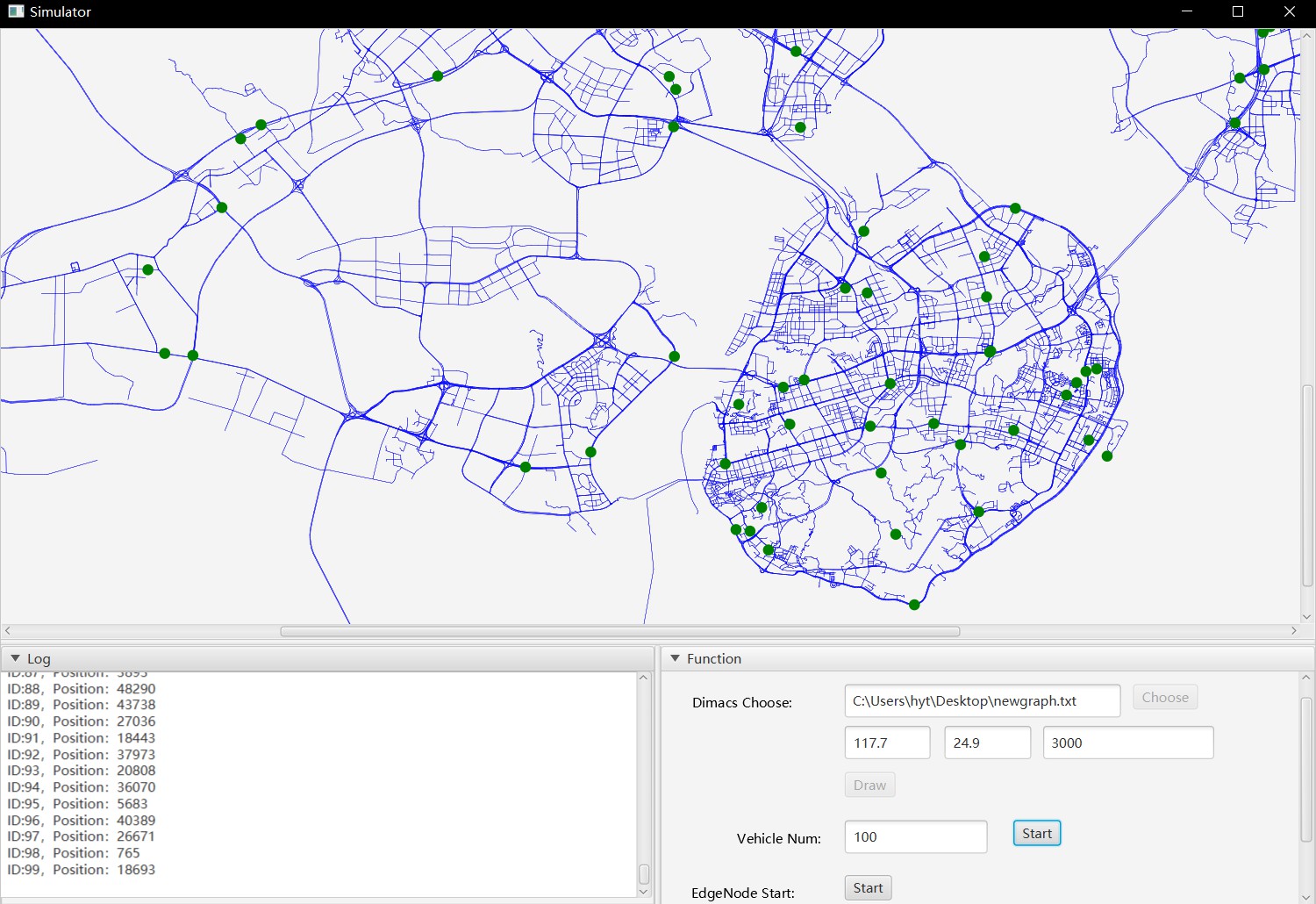
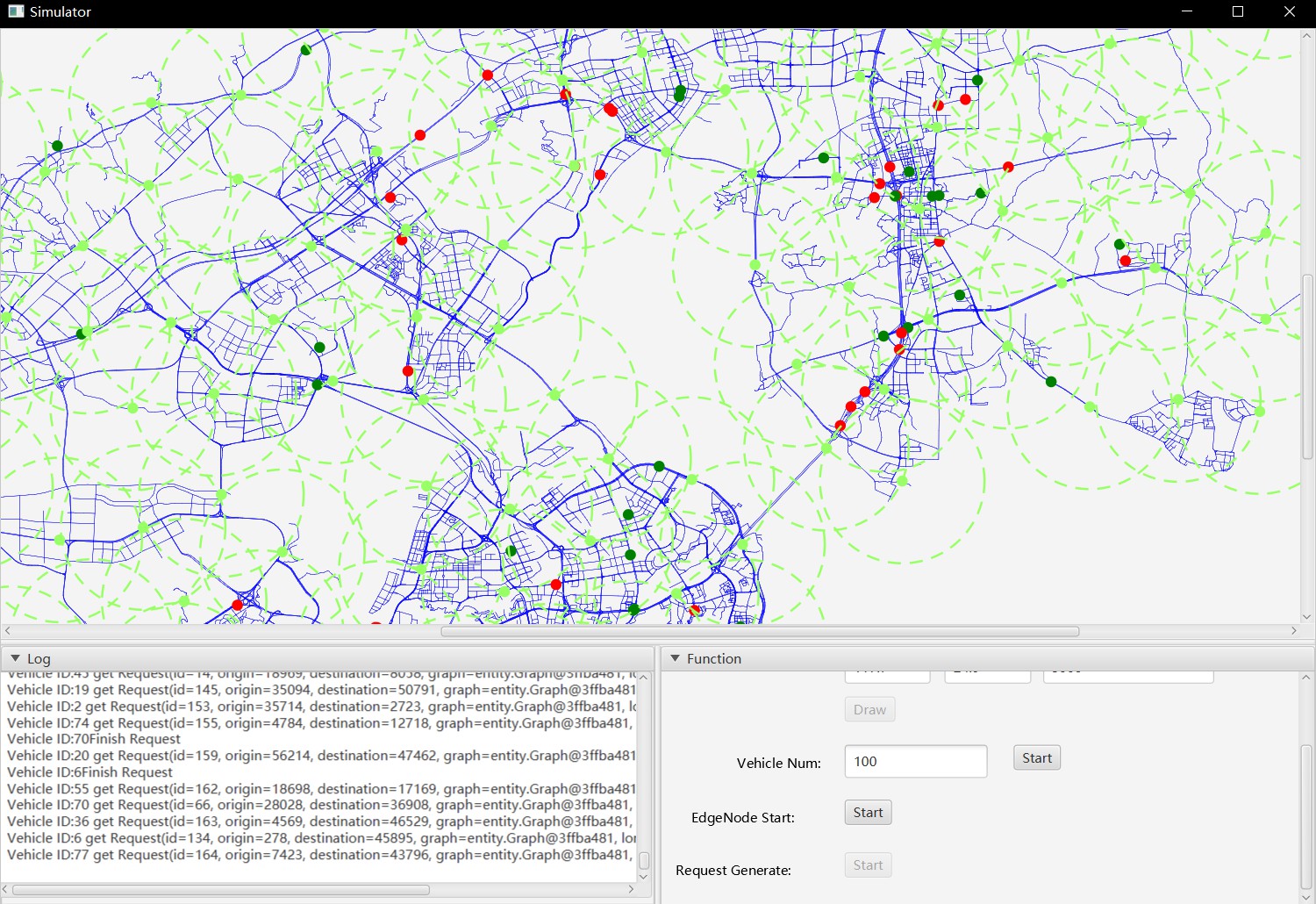
图2 模拟器界面
2 模拟器设计
车联网模拟器主要用于模拟城市中车辆的行驶。 整个模拟器分为三层,图1显示了模拟器的节点结构。 顶层作为整体调度部署在云中,第二层是边缘节点层。 根据网格划分城市,并在网格中设置边缘节点。 作为基础计算节点,边缘节点可以快速响应城市中的请求并执行有效的部署。 底层是车辆所在的节点,是路网部署的实体。

图3 模拟器节点架构
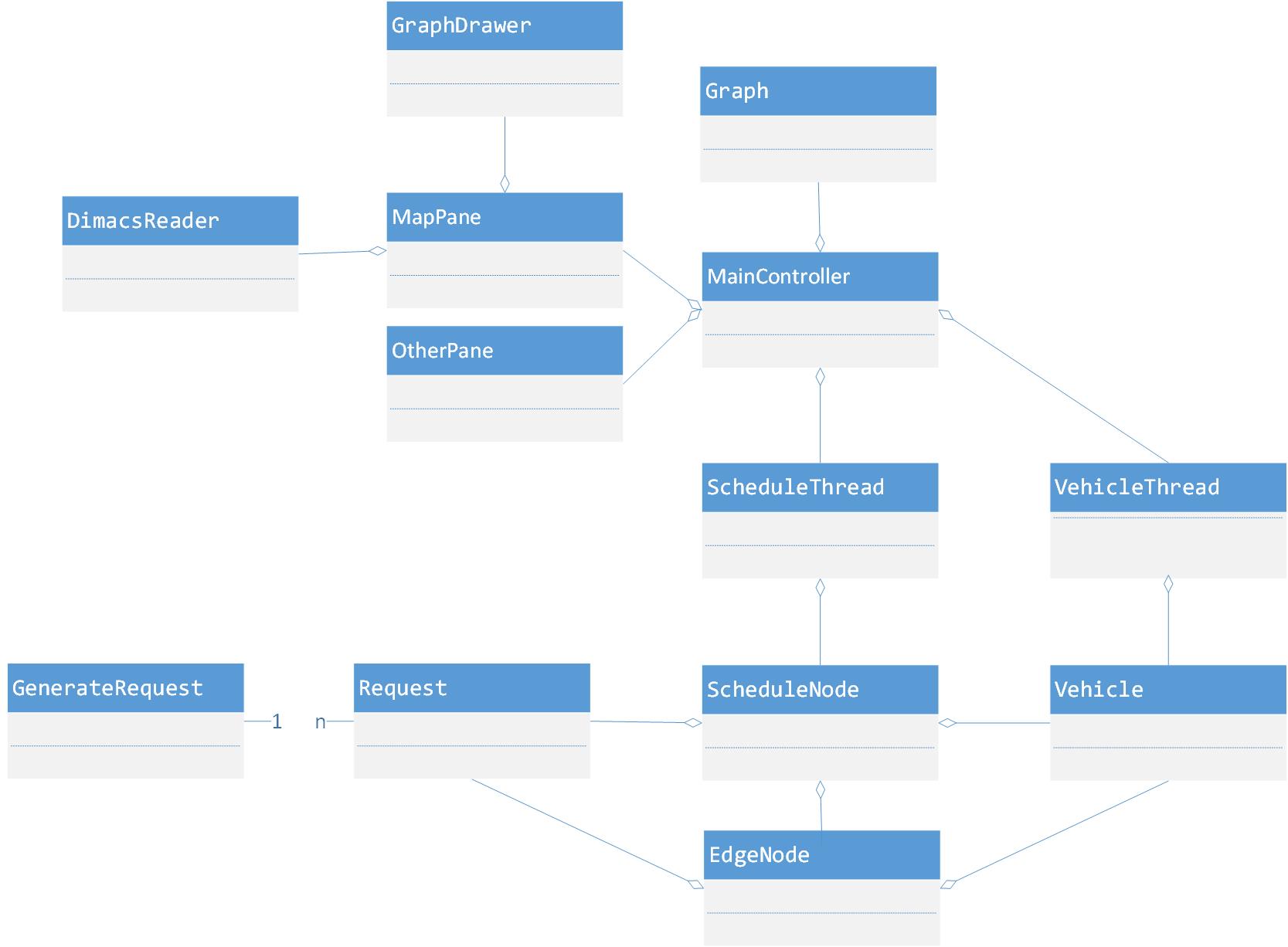
图4 模拟器类图
模拟器希望以JavaFX来开发可视化界面,它比Java Swing和AWT更快,并且在Java的开发中将得到更多支持。模拟器的功能预期可分为以下五点:1)导入并显示城市地图; 2)建立三层节点; 3)设置节点之间的通信协议; 4)在路网中生成并部署请求; 5)展示车辆运动情况;6)统计运行效果(响应速度,丢包率等)
2.1 生成地图
地图的显示是模拟器最直观的功能。 它可以根据不同的导入文件显示不同城市的道路网络,从而使模拟器能够适应多个城市的交通状况,具有通用性。
地图的导入分为三个步骤,1)导入DIMACS文件,2)调用循环清除功能,3)绘制地图。
2.1.1 导入DIMACS文件
道路网络由图形表示,因此导入的地图采用DIMACS格式。 p开头的字段是描述性语言,以n开头的字段是节点的信息,以e开头的字段是描述边的信息。
DIMACS是源自离散数学和理论计算机科学的首字母缩写。 DIMACS格式是一种图形数据格式,以纯文本或二进制形式存储,存储单个无向图,这是图形的常用交换格式。
2.1.2 清除环路
道路网络地图包含大量节点和边线。 导出的DIMACS文件中有大量的回路和连接的子图,这使整个道路网络变得多余和混乱,因此删除了较小的连接子图和孤立的回路。 将整个道路网络连接起来,便于界面展示,也便于后期车辆轨迹的规划和操作。
特定的清除逻辑是遍历图中的每个顶点,将所有连接的顶点存储在数组中,然后将它们导出到新的数据文件中作为用于显示地图的数据。
2.1.3 地图绘制
通过GraphDrawer类对处理DIMACS文件后得到的graph进行绘制,并将结果展现在界面上。
2.2 节点设置
模拟器中的基本单元称为节点。 它包含基本的通讯功能。 根据模拟器的三个级别将其分为三个不同的节点,即调度节点,边缘节点和车辆节点。 这三个节点在不同级别上不同。 角色也不同。
2.2.1 调度节点
作为顶级节点,调度节点通常部署在云中以调度边缘节点。 调度节点的功能主要是管理边缘节点的分布和启用与否。 边缘节点的分布是由调度节点根据城市地图网格划分生成的。 该节点存储当时处于活动状态的边缘节点的图形。 同时,“调度节点”会根据路网的整体情况调整是否启用“边缘节点”。 当车辆和请求的数量较少时,可以适当减少边缘节点的数量,以节省计算资源。
2.2.2 边缘节点
作为基础计算节点,边缘节点部署在非常靠近车辆的道路一侧。 由于调度的车辆是整个城市的车辆,因此数量很大,直接计算顶部节点将导致压力过高而无法加载相应的计算量。 因此,请使用分层模型,添加一层计算层,部署Edge Node进行边缘计算,并减轻主服务器的压力。
边缘节点负责将每个请求分配给相应的车辆。 该请求由节点提供,根据该节点在请求范围内管理边缘节点。 边缘节点在所有受管理车辆中找到最接近请求且未执行请求的车辆节点,并使用Dijkstra算法来计划车辆的行驶轨迹。
2.2.3 车辆节点
车辆节点是道路网络中最小的单元,代表城市中的每辆车辆。每个车辆节点都归属于边缘节点管理,并且每个车辆节点都由ID标识。每个车辆节点仅接受一个请求。
由于每个边缘节点都具有ID和统一的辐射半径,因此将半径内的车辆节点作为车辆节点进行管理。如果边缘节点范围内的车辆已部署到管理范围之外的节点,则根据调度节点存储的边缘节点活动图,找到最近的边缘节点以确定该车辆是否在其管理范围内(如果有)在该范围内,车辆在该节点附近,如果不在该范围内,则找到与原始节点第二近的Edge节点以做出相同的判断,依此类推。如果所有周围的节点都无法管理车辆,则将管理车辆的边缘节点的ID设置为-1。 30秒后,在车辆附近找到离它最近的边缘节点,以确定它是否可以由该节点管理。如果在范围内,则将边缘节点ID设置为管理车辆的边缘节点的ID。否则,每30秒执行一次相同的操作,直到找到管理节点。
2.3 路由
由于当前节点之间的通信只需要满足节点的打开和关闭以及请求的分配,该功能相对简单,因此当前采用的路由协议是直接传递。 采用节点之间的直接通信。 上级节点直接分配下级节点,并且这些节点也具有直接消息传输。 无需设置消息格式。
预期未来的模拟器能够为路由协议设置路由接口,这有助于扩展路由协议。 随着后来的模拟器功能逐渐复杂,可以通过实现接口来添加其他更复杂的协议,例如DTN路由协议和5G路由协议。
2.4 请求生成
模拟车辆的部署主要包括两个方面,一个是部署中所涉及的车辆的状况,另一个是请求的情况。
2.4.1 车辆设置
模拟器需要设置要部署的车辆数,即车辆节点数。 未分配请求时,车辆的初始分布静止。
车辆的初始位置被随机分配给一个随机数。 导入地图时,运动轨迹从初始位置开始沿连接顺序移动。
2.4.2 请求设置
请求设置主要包括建立请求的数量,请求的时间,出发点和出发点。 以多线程方式,每2000毫秒生成一个新请求,并且最多同时并行生成10个请求。
2.5 分配任务
为了处理请求,模拟器以多态方式调用接口。 默认情况下,模拟器使用最近距离原理。 距离请求起点越近,就将请求分配给车辆,并将Dijkstra算法用于从起点到终点的路径规划。
2.6 车辆运行
车辆的运动是多线程的,可以同时操作多辆车辆,并且接口每1000毫秒刷新一次。
模拟器预期在在运行时将设置车辆数量,并按如下运行:1)车辆随机行驶。 2)从配置文件导入车辆行驶轨迹。 车辆经过的节点依次记录在配置文件中。
3 未来计划
将在车辆移动时考虑诸如交通密度和车辆交互作用等因素,并且将为模拟器实现更复杂的移动模型。我们将为模拟器实现其他更复杂的协议,例如DTN路由协议,5G路由协议,并使模拟器适合更多场景。
更多
轨迹数据的挖掘和可视化 Sun Oct 09 2016 22:10:09 GMT+0800 (中国标准时间)
轨迹数据就是时空环境下,通过对一个或多个移动对象运动过程的采样所获得的数据信息,包括采样点位置、采样时间、速度等,这些采样点数据信息根据采样先后顺序构成了轨迹数据。例如具有定位功能的智能手机,轨迹数据反映了手机持有者某一时间段的行动状况,移动互联网络可以通过无线信号定位手机所在位置,进而采样记录,通过连接采样点形成手机持有者的运动轨迹数据;GPS定位终端,固定采样频率的记录终端所在位置的经纬度信息,通过无线网络将数据收集到服务器上;RFID标签技术,对物体进行标记,将物体的移动线路通过RFID识别器完成定位和位置数据记录,形成物体的移动轨迹。
作为数据挖掘的一个新兴分支,轨迹挖掘的研究热点集中在轨迹聚类、轨迹分类、离群点检测、兴趣区域、隐私保护、位置推荐等方面。我们的研究目标是:挖掘轨迹数据的模式,优化实际的交通和城市应用。具体的研究的内容包括以下几个方面:
- 轨迹大数据的存储架构和方法,数据的清洗和预处理:基于Hadoop、Spark等平台存储轨迹数据,进行数据预处理、数据聚类、计算对象相似度等;
- 交通模式分析:基于移动节点(汽车、行人等)的GPS数据,分析行为模式;进行叫车推荐、数据统计和分析等;发现城市生活的规律,并开发有趣的应用;
- 轨迹数据可视化:对基于轨迹数据的交通和城市应用提供可视化优化,提供良好的用户交互界面;
打车推荐 Fri Oct 07 2016 19:32:58 GMT+0800 (中国标准时间)
以手机为代表的移动智能终端已经成为人们生活之中不可缺少的一部分。为了缓解“打车难”的问题,手机打车软件应运而生。项目结合手机打车软件和车载网络(VANET)的背景,基于厦门市真实地图数据和车租车轨迹数据,研究实时监控与历史信息预测并行的打车推荐算法,提高打车的效率和用户体验。
项目成员:吕铮(研一)
更多车载网络数据收集 Sun Oct 02 2016 15:59:37 GMT+0800 (中国标准时间)
车载自组织网络(Vehicular Ad-hoc Network,VANET)又称“车载网络”或“车联网”,是利用先进的信息和网络技术,将车辆、行人、道路和路边设施等集成为一个有机的信息系统,以提供车辆安全、交通控制、综合信息和互联网接入等服务。VANET为人、车、路之间的相互作用关系提供了全新的呈现方式,为智能交通系统(Intelligent Transportation System,ITS)提供了更多丰富有效的应用。我们将研究
- 车载网络数据管理:
车载机会传输模式下的消息分发、数据收集,内容查询和共享机制的研究; - 移动数据模式分析:
在数据收集的基础上,分析移动节点的行为模式和规律(如状态判断、位置预测等);
项目成员: 林志捷(研一) 周策
更多直播流媒体技术 Wed May 04 2016 16:14:52 GMT+0800 (中国标准时间)
项目将研究当前的直播流媒体平台技术,包括:
- easyDarwin 流媒体服务器的配置、使用 ;
- 移动端的视频数据推送
- 移动端视频的接收
- 基于HLS(Http Live Streaming)的流媒体技术
文章
A Learning Based Approach To Predict Shortest-Path Distances ___江丽英
基于半监督学习的工业瑕疵检测方法
基于时空网络和多任务学习的 城市区域交通流量预测研究——江丽英
基于shortcut的时间依赖最短路径估计算法_杨诗鹏
数据分析和机器学习资料推荐
特征抽取:CountVectorizer -- spark.ml
标签和索引的转化:StringIndexer- IndexToString-VectorIndexer
Word2Vec--spark.ml
谈谈如何准备保研面试
每年的6、7月份各个学校的各种夏令营就开始了。很大比例的保研名额会从夏令营里给出,这其实是各高效提前锁定优质生源的一种办法。大三的同学们估计也大抵清楚了去夏令营其实就是去考试和面试的。如何准备面试,对那些有志于获得保研名额的同学,则显得十分关键。本人参加了一些面试,有些体会。因此,也想从更大的维度和大家谈谈保研或者考研中面试准备的问题。本文只有泛泛而谈,具体的面试技巧涉及很少,请大家谨慎阅读。一家之言,仅供同学们参考。
首先,要有战略眼光,清楚面试的目的,了解面试官的述求点。面试过程中的正规性、公平性毋庸置疑,学校和老师们都非常重视,会屏蔽掉一切可人为操作的空间。比如,考官一般都是由本系的教授组成,考生的名单对考官是不可见的,考官也只有在面试当天才能知道自己所在的分组。面试过程中的一个重点就是以确定学生是否适合读研,是否具有科研的潜力。对目前国内的大多数高校而言,老师以科研为主,硕士研究生仍旧是科研的主力军。因此,面试过程也大都是围绕这个目标来执行的。比如,如果考生英语能力好,未来的科研论文的阅读和写作能力也可能较好;本科如果有科研写作或者参与实验室项目的经历,可能更能融入未来的科研实践中。而这,也是面试过程的几个基本模块。因此,了解面试的目的,了解面试官的述求,学生们就可以换位思考,“投其所好”,更从容地参与面试。
其次,是在心态上调整好,最好地展现自己的闪光点。能够入围夏令营,到了保研或者考研面试这个阶段,基本已经证明了你之前的能力和学业水平。因此,面试的重点不是再重复地展示你的过去,而是要能够展现你的潜力和可能性。特别是如果能够展示“人无我有”的闪光点,则几乎成功了一半。因此,没有必要太过紧张,只要把自己的特点有效地表达出来,就基本成功了。想要通过面试大力提升和凸显自己的没有的特点或者优点,经常是不太现实的,我一般不太推荐考生这样做。因为,大多数情况下,通过一些问题的对答,评委可以轻松地识别出来你是否是真材实料。当然,放松并不意味着无所谓。在面试过程中,也曾碰到一些同学,表现得通不通过都无所谓。这样太过放松的心态,会给评委留下不太好的印象。那好的心态是什么样子呢?我的感觉是表现得举重若轻,同时又谦虚谨慎,积极进取,这样的状态是极好的。
然后,就是具体的面试技巧了。我相信这部分是很多同学最感兴趣的,也是有一些前例可以参考的。首先,要了解到往年面试的基本题型。同一个学校同一个专业的面试流程,一般都有持续性,不会有太大的变化;而不同学校之间的面试可能差异比较大,要提前了解。所以,可以提前联系一下学长学姐,从那边获得一些往年的面试经验及信息。如果在本校,则这个信息不难获得。如果你考的是外校,发现身边没有这样的学长,也完全不认识对方学校的人。这个时候,当然是千方百计找到可能有关联的人。可以问朋友的朋友,可以找老师,可以发邮件。总之,在这个“任何两个人之间只有6跳”的世界里,如果你想联系到一个人,转几个弯,肯定可以找到。这其实也是一种能力,就是你是否有获取信息、充分利用资源、整合资源的能力。其次,要多一些面试的经验和常识。大多数面试都是一样的,考研或者保研面试其实是一种结构化面试,和求职找工作等的面试没有本质区别。因此,你在其他地方看到的面试技巧,注意事项等等,在考研和保研面试中都是适用的。考官也通过你的仪态仪表来考察你的综合能力和素质。所谓的印象分,就是从这来的。保研面试里面,除了考察你的科研潜力,评委们其实还在考察你的沟通、表达、应变等各种能力。
作为求学路上一个十分重要的关卡,面试是学校选择优秀学生,也是学生选择学校和老师的过程。好的学生到哪里都是受欢迎的,如何留住优质生源,找到好的学生,其实是目前高校普遍面临的一个问题。我们老师调侃时时常说的一句话是:本校的好学生时常外流,而外校的好学生我们可不能让他跑了。而同学们透过面试过程,也可以看出学校的水平,看出老师的水平。我所遇到的大部分老师,也会尽力做到公平和专业,尽量给学生留下好的印象。
最后,祝有志于保研和考研的同学们报考厦门大学软件工程系——一个拥有“国家级人才培养模式创新实验区”和“国家级一流本科专业”的系。如果你对软件工程系的保研和考研面试有疑问,也欢迎通过邮件联系我。我会尽可能地解答大家的问题,但最好请能够在邮件中先介绍下自己。
培养研究生的方式
近年来我开始开始带研究生了。回顾自己的研究生求学生涯,观察我的导师,同事,以及所认识的朋友带学生的方法和方式。我一直在思考一个问题:如何带好研究生,让他们在短暂的几年时光里有所收获,有所成长;同时,导师/课题组也能有所收获,双方都受益于这个过程。
我把对于研究生培养过程的一些想法写于此,与大家交流。希望本文能够给那些有志于读研究生的同学以一点启发。
1. 师生关系是一种美好的互动关系
这个是我目前为止的认识。我很幸运,想起来硕博期间的导师,想起教过我的老师,内心是充满温暖的。可能我选择的导师都是很Nice的人。毕业多年了,我的同门还是很尊敬他们,愿意和他们保持联络。这种关系,是我思考师生关系的起点。我倾向于把师生关系放在十年、二十年、三十年的维度去思考:培养一个学生,其实为社会培养一个栋梁之才;这个成就感,在很多的时候,是教师这个职业最大的意义和报酬。
研究生(或博士生)导师,不同于本科的教学老师,也不同于高中的老师。师生关系更像是一个“一对一”的学徒关系,有更多的个人交流和时间上的相互投入。因此,研究生期间的师生关系,是一种较为密切的互动关系。人是多变量的系统,人与人的交互涉及的变量也比较多。时至今日,学生的培养过程仍旧被看做是一个黑盒子。输入变量是学生、老师的属性,输出是学生的能力和品性。但实际上,变量远不止这些,还存在很多的隐藏变量和外部变量。比如,学校的平台、社会环境等都是影响的变量;而老师的能力和品性,其实也是输出量的一部分。在这个过程中,学生和老师既是输入变量,也是输出变量。学生的培养过程在深刻的塑造学生,也在影响着老师,影响着学校,影响着社会。 所以,当老师愿意更多的去成就学生,帮助他们,为他们争取资源的时候,其实也是老师成就自己的时候。好的培养过程会让社会收益,让生活更加和谐美好。
2. 学生因人而异,目标意识很重要
一个人的内在目标和驱动力,是决定一个人能否“成功”的重要指标。这里的成功加了引号,想表达的是“成功”并不只是世俗意义上名和利的成功。在我看来,成功并无固定模式,每个人兴趣和志向不太相同,所以成功的标准也不太相同。即便如此,社会对于成功是有一个大体的认同标准的。一个人的事业做的好不好,通过横向比较和历史的纵向比较,是有一个大概客观标准的。
但总是横向比较,也容易导致“人比人气死人”。人的机遇不同禀赋不同,因此,只是看结果其实没有太多的参考价值。有一个我比较认可的关于成功的定义是:在施加于你的各种限制条件下,达到个人潜力的充分发挥,实现自我的目标。在“什么是成功”的议题上,个人提倡应达到“自我认同”和“社会认同”的基本统一。即参考社会的成功标准,同时也在心里有一个“内部积分卡”。规划自己的人生道路,定义可达目标,并按照这个目标去努力实现;最后实现了,获得了喜悦和成就,这就是你的成功。
因此,我希望能够身体力行。和学生一起规划目标,目标落实到年、月、周、天。如果每天、每周、每月、每年的目标都实现了,那么我们就是在不断的向自己的成功靠近。
3. 老师站在前沿,学生能发挥潜力
研究生培养也考验导师的水平。虽然说“师傅领进门,修行在个人”,学生个人的努力和天赋,占据了很多的权重。但不可否认,一个好的老师,在学生成长过程中,很可能就是那个关键的1%或者10%。这也是为什么学生们在选择导师的时候,总希望找一个好的,适合自我发展的导师。
一般的统计结果而言,好大学出来的学生优秀的比例高;好的老师带出的学生的优秀的概率也比较高。好大学有了大学排名和专业排名,那什么样的老师才算好老师呢?这个评价标准包括了太多的方面了。可以从道德方面评价,从性格方面评价,可以从学术水平评价。从学科和学术的角度来看,我觉得老师应该能够站在前沿,为学生指引方向。他不一定是学科大牛(真正的大牛不多),但至少知道大牛们在哪里,学科关注的焦点在哪里。做到这一点,其实也不容易。它要求老师在专业能力的基础上不断学习,跟进最新的科研和技术。在此基础上,导师为学生提供指导,一起探索新发现,实现新的想法。这个过程,其实是师生共同进步的过程。理想的最终结果,应该是双赢,老师的专业水平提升了,学生的水平也跟着提升。当学生的能力和潜力都得到最大的发挥,就应该有“青出于蓝而胜于蓝”的结果。
值得指出的是,研究生培养周期是2到3年。当前研究的热点,可能以后不再是热点,但这个过程中,学生经历的完整的“把一个课题做好,把一件事情做好”的过程,领悟到的做人做事的态度和方法,很有可能会极大的影响学生的未来之路。爱因斯坦说过,“教育就是当一个人把在学校所学全部忘光之后剩下的东西”。这个说法,也符合研究生的培养过程。
4. 刻意练习,慢就是快
“刻意练习”是最近流行的一个概念。我直接拿过来用,觉得很切合研究生的成长过程。首次提出“刻意练习”这个概念的是心理学家 K. Anders Ericsson。核心假设是,专家级水平是逐渐地练出来的,而有效进步的关键在于找到一系列的小任务让受训者按顺序完成。刻意练习被证明是很多领域成功的方法论和关键。对于研究生的培养而言,也不例外。
于“工学”研究生而言,最重要的能力就是工程能力和动手实践的能力。具体到软件和计算机专业,就是编程和解决问题的能力。这种能力也是目前企业最为迫切需要的能力;而创新性研究的能力,则被认为是博士阶段的培养目标。因此,学生可以用“刻意练习”的概念,去逐步增强自己的能力。一般地,我会列出一个研究方向的知识点,我称之为“知识点地图”。地图上有具体的知识点,一些是需要精通的,一些是需要了解的;一些是需要仔细看书研读的,一些是要要学会,但可以网上便利获取的。我会要求让学生按图索骥,有意识的去巩固和掌握这些知识点。这个过程中,培养的是学生学习的能力和自我驱动的能力。这些知识点所代表的能力,最终也能够让他们轻松的找到理想的工作。
“知识地图”上的内容和知识点不少。急躁的学生容易放弃;而沉下心来慢慢学习,肯下功夫的同学,最后能力一定可以大大提升。这个过程,就是练习的过程。所设计的知识点,不是1天可以完成,不是1周可以完成,甚至不是一个月可以完成的,而是2年或者3年要完成的。这个时间跨度,要求学生能够合理的评估自己的时间,能够做目标分解,能够循序渐进,能够以慢为快,用笨办法夯实基础,达到最好的学习效果。
5. 实际主义的研究
什么是“科研”,怎样才算是在做研究呢?
我也是大学毕业后,懵懵懂懂的跟着老师和学长们开始所谓的研究生涯的。04年开始读研,算起来也有14年了。科研到底是什么?有人觉得科研就是在研究理论,写论文;有人觉得研究就是做实验,做项目,诸如此类。其实这些观点都对,因为不同学科的科研表象上看,是有些差异的。理论研究和工程技术研究,都是研究,但需要的资源、人的才智、和所使用的工具可能很不一样。
对计算机相关学科而言,大多数是在研究更优化、更高效的算法,设计一些更好的系统。浅显一点看,大概是除了编程、实验、把一个demo做出来之外,还能基于数学、概率、复杂性分析之类的理论,进行抽象和拔高。计算机的一些顶级的学生会议,也经常涉及这些理论的创新。但也有些时候,一些复杂的公式和算法,只是为了抽象、装饰、和解释一些东西,不完全了解也没有关系。毕竟,计算机和软件本身是一个大的学科群,包括硬件、嵌入式、图像图像、操作系统、信息安全、数据科学等等。即便数据科学,也是一个大类,与数据库、数据挖掘、机器学习、知识图谱等等互相关联。我们所在的软件和计算机学科渗透非常广,在各个行业,各个领域的应用相当宽泛。一个人或者团队,也不可能在任何方向都是行家高手。因此,更可能的情况是,仅在2-3个领域研究得比较深入,而其他的领域,也只是知道个大概。
幸运的是,计算机和软件专业目前是个热门学科,与工业衔接非常紧密。这个学科背后其所代表的信息产业和互联网行业,是一个拥有巨大产值的行业。耳熟能详的几个高科技企业Google、Facebook、腾讯、阿里等等,都是工业界里研究和产业同时做得很好,科研与实际业务深度融合的巨无霸公司。近年来不断地蹦出来的新概念,比如物联网、大数据、人工智能、区块链等等,都是来自于这个学科群。因此,虽然身处高校,老师和同学们也有大量的机会与工业界进行交流合作。在这个过程中,我也慢慢的梳理一些想法:
1) 科研是细致分工的活,工科科研尤其分工明确,平台作战。一个研究者成果列表,其实代表的不仅仅是他个人的能力,更是他背后站着的科研平台,研究生、博士生、学术人脉等各方面资源的综合反映。一个研究者的背后,其实是一个实验室的师生团队。
2) 工业和学术研究的界限正逐渐模糊。至少在计算机领域,目前的学术研究和工业研究,其实是相互促进相互融合的。
3)技术只有通过产业和转化,才能带来更大的价值。技术研发是一种投入,是成本。只有通过技术转化,提升生产效率,产生为用户接受的新产品,才可能真正的创造价值。
从个人的兴趣出发,从所处的平台和环境来看,我还是更加愿意继续在学术研究和工业研发之间做个衔接,在这个越来越靠拢的“产-学”中间地带穿行,做一些真正有用的,对企业和社会有帮助的研究和研发。同时,这个过程中培养的学生,也可以真正的学到知识和实用的技术,拥有可以安身立命的技能,拥有更好的前途。我的实际主义的研究观点,大体基于对计算机和软件学科、一些科研研究院的、以及所在厦大软件学院现状的一些认识。以后有机会,可以更加详细的谈谈这个话题。
6. 进取精神和开放心态
厦大的校训是“自强不息,止于至善”。
“自强不息”指自觉地积极向上、奋发图强、永不懈怠。最早见于《周易·乾》:“天行健,君子以自强不息”。 “止于至善”,语出《礼记·大学》:
“大学之道,在明明德,在亲民,在止于至善”。指通过不懈的努力,以臻尽善尽美而后才停止,也就是说不达到十分完美的境界决不停止自己的努力。所谓“明明德”,即彰明自己天赋灵明的德性,也就是通过学习和实践发掘光大个人内在的优良品德。所谓“亲民”,即亲近、爱恤人民,时刻为人民的利益着想。
好的格言总是普遍性的,放在很多场合都能用上。在培养学生,激励进取,努力奋斗,高目标严要求方面,我们的校训总是灼灼生辉,激励一代又一代的厦大人。
在这里,我想说校训之外的另一层意思,就是开放的心态。做学问和做研究,大概是一个”大胆假设,小心求证“的过程。必然会涉及到对他人意见,他人成功,他人方法的甄选和对比上。而这个”大胆假设“过程,特别需要有开放的心态和创新的精神。就是一开始,不给自己的思维加太多的束缚。在选题上,方法上大胆的去假设,然后去验证和实现,方可能有好的成果出来。同时,在对待同行批评、老师评价等方面,也不妨抱着开放的心态去接收。特别是对于自己不了解的人和事,不要轻易下断言。对于自己的的观点,梳理形成这个观点的过程是否是经得起推敲,是否符合逻辑、是否是可信任的。如果你发现自己的一个观点,其实经不起推敲,或者被证明与事实不符的时候,要有足够的开放心态去改正,要有勇气去承认之前的错误。
开放的心态,永远是一个学习者的姿势,永远从自己的错误,从周围的人,从所处的环境中学习,学习,再学习。
研究生培养的过程和方式,因老师而异,因学生而异。目前,该文只是《研究生培养的方式》思考的一部分。所涉及的内容并不全面,有些观点还可能是错的。但是,我希望能够不断的改进,不断的补充,直到感觉满意为止。希望可以和同学们一起努力,做到最好的自己,达成个人的目标。在最美好的时光里,有最美好的收获。
前端开发的技巧和经验
竞赛评审有感
目前针对大学生创新创业、软件外包服务、大数据等方面的赛事越来越多。有全国性的、有区域性的,甚至还有市一级的赛事。最近几年我也带过几届学生,也有幸作为评委参加过几个赛事的评审。因而,时常也有学生来问我一些问题:该如何选题?该怎样在比赛中获得好成绩,并脱颖而出?这些问题都很实际,也很重要。因此,我就结合个人的经验谈下看法。看法仅限于个人的感受,是个人观点,有兴趣的同学可以和我联系并一起深入讨论。
首先是选题和组队,这是赛前应该做好的工作。对于非固定题目的赛事,选题可自己结合热点选一个;也可以和老师沟通联系。这里,需要避免的一个误区是,选题不要都只从自己的身边入手。作为学生,大家的生活圈就这么点,容易雷同。比如,前几届,发现类似校园、课堂方面的题材比较多,也就不太容易形成亮点。当然,这个选题雷同的趋势也有所好转。组队方面,定一个参赛的目标,组成一个有战斗力的队伍,非常关键。组队甚至比选什么题目更重要。一个好的团队去找老师,老师可能会给你一个很不错的题目。在科研实践中,老师经常有一些想法,容易做成demo的那种想法。但苦于没有人可以实现,或者没有一个好的团队帮助实施。因此如果有一个好团队,就成功了一半,就可能把事情做好。好的团队,能够自我激励和管理。理论上,辅导老师一般时间有限,不可能进行事无巨细的指导。因此,团队能否基于目标进行自我激励和自我管理,决定了他们能否产生良好的项目预期。 此外,评审过程中虽然每个赛事的侧重点会有不太一致的地方,大家要先熟悉各个赛事的评价标准。但从各个赛事的评分项来看,其实大同小异,最后都落实到评委的综合判断上。在复赛的时候,一般上时间都非常紧,不太可能完全严格的按照评分项来计算分数。因此,一个项目的总体创新性、完整性,总体上的好印象是非常关键的。那么,有哪些地方需要注意的呢?以下我罗列了一些,重要性不分先后。大家可以逐条思考,逐条批判:)
- 作品的视频质量、交互性比较重要;视频最好配有有音频、介绍。评审一大部分的印象分是来自于视频;
- 写的文档,也进行格式清楚,有逻辑性,对核心的技术描述要清楚,不要藏着掖着;
- 创新点和亮点很关键。分清楚自己团队的共享和已有的东西,如果是模式创新,说清楚你和别人不一样的地方;
- 演示过程要简洁,突出重点。很多人还在讲解“用户注册”之类的功能,浪费时间;
- 完成度非常重要,功能完备、不能太简单;比赛毕竟是在与其他团队竞争。发现有些idea不错,但完成度不行,也得分不高;
- 一些模式创新的项目,最好可以说明你要解决的痛点,能够带来的价值在哪里?如果能说清楚与已有产品的区别、与竞争对手的区别会更好;如果项目已经商业化运作,请说清楚商业前景、融资计划、竞争优势。这是加分的点。
另外,在初审后还可以进一步改进的赛事(如intel杯),持续改进是关键。比如,在某次评审中,发现初赛排名前10的队伍居然只有一支队伍进入了决赛。复赛中真正脱引而出的,大部分是10-30名的队伍,因为他们在后期做了更多的改进。同时,复赛时的现场演示,一般用采用的是ppt,有严格的时间限制。PPT是否用心,是否做了大量的前期准备,评委都可以看得到。现场演示时候,最好完全准备好,避免关键时候掉链子。
最后,祝大家比赛顺利,拿到理想的成绩。也欢迎有志于课外实践和比赛的同学和我联系(邮件即可)。
程序员的月饼
这是之前写的一篇论文,月饼门也已经慢慢冷却了,快被遗忘了。但仍旧发出来吧。
最近,有一件事情闹得沸沸扬扬,即阿里的“月饼门”事件。相比其他行业,技术界的新闻一般都弱弱的。这次居然也让大家谈论起来,实在值得稍微研究一下。作为软院的小伙伴,可能后知后觉。但如果不知道此“门”为何物,赶紧baidu并面壁思过去吧。
事情是这样:
9月12日,阿里巴巴在内部搞了一个中秋抢月饼的活动,不过安全部门的4名员工却写了个脚本自动抢月饼,不动声色地刷了124盒月饼。随后阿里巴巴作出决定,开除4名涉事员工。
随后网络新闻和评论劈天盖地。大家关心的问题集中在:阿里作为公司,这样做对不对,解除4名员工合法吗?被解雇的员工是否很冤枉,他们伤害到其他人的利益了吗?抢月饼之前,阿里有规定不能用js刷网页吗?……当然,更有人的问题是这样:阿里月饼长什么样,真有这么好吃吗?
道德、法律的讨论已经太多,大家可以各自评判。而作为技术咖,我今天要讨论的话题是:
程序员,你真的很喜欢吃月饼吗?
哦,说错了,说错了。我要说的是:程序员,你为什么这么喜欢写脚本?
不做道德评价,看到这个新闻的当时,我隐约有点同情这些阿里员工。这也可以理解,他们如果是学计算机或软件专业的,我甚至可以想象他们的样子。我现在班上的某某同学,很可能就是这样的阿里员工。动手快、能力强,很有自己的想法,甚至还有点小聪明。这类同学,如果是做课程设计,往往能给我一些惊喜。有点创意,实现完整,做出的小软件或者网站都是基本可以运行的。而且,他会告诉你,他的程序是如何组织的,哪些代码进行了复用,哪些模块可以扩展,哪些地方可以省去很多手工的步骤。
是的,软件其实一直强调代码重用、可扩展、自动化,从而提高开发的效率。“不要重复发明轮胎”——这句话深深的刻在了每个学软件和计算机的同学的脑海里,挥之不去。因此,凡是学过编程及计算机的同志,估计都有一个习惯:极不情愿做重复的事情;如果一定要做一个动作很多次,一定得让电脑或程序来做。因此,脚本和脚本语言流行的动力源头,是那些逃避重复的程序员。脚本可以用来配置程序、系统,和软件。比如,软件测试用的脚本,可以避免测试人员每次的数据输入、鼠标点击等机械枯燥的事情。因此,当秒杀的时候,发现每次都要输入验证码,而验证码会影响你的秒杀成功率的时候,一个典型的程序员能想到的,自然是如何避免每次的手动输入了。据说,当初热闹了一阵的火车票刷票软件,也是用的这个原理。从这个角度来说,没有想过减少重复操作的程序员,都不是好司机^_^
然而,任何事情,技术之外还会有法律和道德的因素。在互联网时代的今天,我们追求简单,去除中间环节,减低交易的成本。但仍旧有一些东西,我们会人为的设置障碍,故意造成一定的低效率。而其目的,其实是为了达到一种所谓的公平和正义。虽然,社会很难有绝对的公平和正义。这也是为何,有人觉得被开除的员工很冤枉,也有人支持马云的铁腕做法。但作为一个正在从事技术研究,讲授编程技术和思想的教书先生,我支持大家按照技术的逻辑,不断的去尝试和创新;但同时,也建议大家可以从更高的维度来思考问题。
即,在技术之外考虑技术,从而看见我们这个时代的限制,思考这个时代的机会。因为,除了代码,除了月饼,这个世界还有很多其他的事情需要我们去听、去看、去想呢。
MOCOM课程系统常见问题和说明
1. 如何登录mocom课程系统?
请和老师或者助教联系,获取账户和密码。
2. 账号和密码登录不了怎么办?
如果发现无法登录(不存在账号)的同学,需要自己注册账户。然后通知老师,老师管理员后台通过即可。
3. 选课密码是什么?
每个课程的选课密码不同。一般在对应的QQ群里面,老师会给出。
4. 如何进行课堂点名?
疫情期间,将通过QQ群投票的方式,确认大家是否到场听课和学习。平时线下,则通过mocom系统进行点名。请大家按上课时间,准时在线上参与学习。
5. 如何提问题,如何回答别人的问题?
方法1: 可以在课程主页,在每个章节发表课件的后面,点击“评论”,写下你的问题。 老师、助教和其他同学,都可以针对你的问题进行回复。
方法2:可以在QQ群直接提问,但要标注【提问问题:】四 个字,并把问题描述清楚。老师、助教和其他同学,都可以针对你的问题进行回复。
我们非常鼓励同学们互相讨论,互相帮助,帮助回复其他同学的问题。老师和助教将不定期的针对大家的问题进行总结,并在课堂上给出答复。
6. 如何提交作业?
按要求的格式提交到学院的ftp。不要在mocom系统上提交。提交的时候,请注意ftp上对于提交作业的文件命名的要求。
7. 如何进行发布作业或进行课堂小测?
老师将在mocom系统或者qq群发布作业或进行小测。同学们须在规定的时间按作业要求,提交作业。
8. 如何与老师沟通?
针对课堂的一些建议和问题,大家可以发邮件到laiyx@xmu.edu.cn,或者qq私信给我。欢迎大家的意见和批评。等疫情过去,也可以提前发邮件预约面谈。我的办公室在 海韵行政楼A302。
实验报告/教程写作说明
一、预备知识:
1、 markdown的基本语法
https://www.jianshu.com/p/q81RER
2、markdown编辑器的使用
windows:[MarkdownPad - The Markdown Editor for Windows markdownpad.com/](http://markdownpad.com/)
mac: Typora
二、实验报告/教程的提交:
实验报告,也称为实验教程或者Tutorial。本课程要求实验报告以“**详细教程**”的方式提交:
1、每次实验的内容和要求,将发布在课程的主页上;
将指派不同的题目给同学
2、实验完成时,把文档提交到ftp的对应目录和文件夹;
提交的内容包括:
1. 程序源代码的project,压缩成一个包 2. 对应的markdown文档 3. 文档对应的图片等其他资料
把以上的内容放相应的目录,目录规则是:
学号后4位+姓名+实验n+实验标题
比如,
“5013+张三丰+实验1+**安装和控制台程序” 放到目录“实验1”
“5013+张三丰+实验2+基于html5的时钟” 放到目录“实验2”
请提交到学院的FTP服务器:
121.192.180.66
三、如何写一个实验报告/教程
- 请先仔细阅读文档:
《如何写好一个技术教程》 http://mocom.xmu.edu.cn/article/show/5e3f7e1b312f7a541546c28e/0/1
- 参考网上不错的教程,看他们如何组织内容,进行说明:
https://blog.csdn.net/sD7O95O/article/details/78096251
https://ken.io/note/dotnet-core-qucikstart-debug-vscode-skill
https://machinelearningmastery.com/visualize-machine-learning-data-python-pandas/
https://machinelearningmastery.com/gradient-descent-for-machine-learning/
- 一个实验的教程/报告,请按以下思路进行组织:
引言:给出实验目的,tutorial的任务
环境:给出环境设置、工具等
具体过程:可以分步骤,有代码,有截图。以图文并茂的方式呈现
总结:总结内容,强调重要的点,以及知识点拓展、讨论等
四、持续改进和提升
- 完整的技术教程,可发布到课程的网页上
- 大家互相可以评论,并不断优化
- 可适当参考网络的教程,但必须是自己的代码和截图
如何写好一个技术教程
引言:
写技术教程的好处和意义,不再赘述了。大家写过几篇之后,会有更深的体会。那么如何写一篇好的技术教程呢?这是初写者下笔时,容易困惑的时候。在本文中,你将学习写一个技术教程的方法。具体包括以下内容和步骤:
选择一个好的写作工具;
构思主题,选择读者受众;
从读者的角度,设计教程框架;
分步骤展开,细化框架;
用图片和表格来描述;
总结,指出重点和其他关联;
参考文献
-
选择一个好的写作工具;
推荐用Markdown的工具。简洁友好,支持代码高亮、latex公式输入。而且更关键的是,可与发布平台Wordpress无缝对接,可方面的导入。Mac上,推荐Typora。
-
构思主题,选择读者受众;
技术教程可以是一篇,也可以是一个序列。如果是序列文章,可以以某个技术模块为目标。写第一篇之前先构思,拟一个序列主题,最后形成一个序列的文章。这样成体系的介绍,对阅读者而言更有价值。
而读者一般预设以初学者为主。一个序列教程的好处是可以由浅入深的介绍。没有基础的读者,可以从第一篇开始逐步往后看;而有基础的读者可以略读,或者跳过前面的几篇,直接阅读后面的内容。
-
从读者的角度,设计教程框架;
想要写的主题是是作者已经学过或精通的内容。作者一般会从自己的学习过程为出发点,逐步介绍。这种方法有可取之处。但更重要的,应该换位思考。思考这个主题,有哪些前期的基础知识需要交代,有哪些难点、重点,并联系自己学习过程中遇到的困难,合理的设计教程的框架。
一般来说,框架可以采取”总-分-总”的结构。从问题入手,先写“引言”。引言部分引入问题,然后总括即将要介绍的内容或步骤。然后引入必要的基础知识,展开具体的描述,最后做总结。对于一些重点,难点,应该帮助读者指出并强调。在总结的时候,也可以再次重复,帮助读者梳理、吸收和记忆。
-
分步骤展开,细化框架;
分步展开,则是对内容进行细致的描述和介绍。
一般的,技术教程以案例驱动进行解释。通过例子的操作和实现,展示具体的步骤和细节。案例的选择,可参考其他的教材和教程,但具体的问题最好是原创的。特别对于数据分析的技术教程,永远可以选择一个自己熟悉、又不同于他人的数据集来实作,并给出操作的结果。
其次,考虑段落和句子的连贯性,逻辑性,注意断句和段落安排。一个标题对应一个主题,一个段落对应一个主题,通过形式上的安排,合理安排教程的逻辑,做到逻辑严密,上下衔接,层次分明。值得指出的是,一个优秀的教程应该能够指出重点,指出学习者容易犯错的地方,针对读者可能遇到的问题给以解答。针对性的对一些内容给出适当的解释和强调。
在展开的时候,也特别注意文章前后的呼应。特别是对于系列文章,一般要求采用统一的案例和数据,使用统一的行文风格,保持连贯性,方便读者理解。
-
用图片和表格来描述;
技术教程除了文字,还需要有代码,截图,表格等进行说明。一个基本的方法和要求是,充分的利用代码高亮,行号,操作截图,运行截图等,进行解释和说明。除了问题,能够用图片、截图和表格进行说明的,尽量用这些元素进行说明。拥有良好展示性的教材,将让整个文章的内容生活起来,有更好的表现力和解释力。
-
总结,指出重点和其他关联;
最后,需要对关键内容进行概括性的总结。把你最希望读者学习和记住的内容,做个简要的重复。如果是序列中的一篇,也应该引出一篇技术教程的内容,吸引读者继续阅读;如果是系列教程,也可以推荐其他系列的内容,介绍读者可能感兴趣的其他内容和资源。
-
参考文献
每个教程有参考的资料和文献。有转载和借鉴的书籍、论文、博文、教程等,都应该标出出来。特别的,给出博文的链接,承认其他写作者的贡献。
就先介绍到这里吧。一个好的技术教程,将有很强的生命力。它将影响很多人,也节省很多人的时间。而通过写作输出,写的过程中作者本人也将梳理自己的思维,深化对内容的理解。表达自己,输出知识,既是一种认知上的升华,也能极大的提高个人的沟通能力。
多写,多练习,多输出,就是在不断的打磨你的写作能力,你的技术教程也将越发精彩,更有价值。
彩蛋:
作为彩蛋,在此公开一个写好技术教程的秘诀——修改、修改、继续修改n遍,n趋近于 。
。
写完后的初稿,一般都只是半成品,存在各种各样的错误。因此,除了自己多读几遍,也可以请同学朋友读一读,修改各种错误,调整前后句子及逻辑。有可能的话,把稿子放几天后再看。多审视几番,直到自己觉得满意了再发布出来。当教程发布了,通过读者的评论,你可能会发现一些错误和可改进的地方。这个时候,还有继续修改的空间,还可以在“止于至善”的道路上继续前行。
18-19学年的总结
该如何考试和被考试
大学的考试很多,考不好,会挂课;考得好,可以得奖学金,更容易升学。每次考完,都是几家欢乐几家愁。当然,考试和考试是不一样的。大学读书的时候,看过一些同学考前突击一晚,就能拿个90分。这些课程通常比较水,是一些软课。而有些硬核的课程,是不可能这样去突击的。总体而言,我不太喜欢那样的软课,不喜欢那种考试和考卷,总觉得轻易的抹平了平时兢兢业业上课、切实掌握了知识的同学的努力。因为有了这样的考试体验,也是这样考试着过来的。等到当了老师,我会比较关注考试和试卷的区分度问题。考试的区分度,涉及到课程的公平和公正问题。虽然考卷无法衡量所学到的全部知识,但公平公正的原则是大家必须遵守的。公平的核心,是用同一把尺子来丈量学生。就是说,要难大家难,要容易大家容易;考卷自身的设计倒成了其次的问题。
但是,绝对的公平总是很难获得。在大多数情况下,公平其实是一个稀缺品。大学被称为象牙塔,除了有脱离社会、不问世事之意,还有就是老师和同学都比较理想化,都会往公平和公正的方向去追求。所以,个人认为,维护考试和课程的相对公平和公正性,是老师应到追求的。让付出和回报成正比;让掌握了课程知识的同学获得更多的收获;让不认真的同学,受到一个负的反馈(惩罚)。我有时候也把考试当做学生最后的课程学习。因为复习的过程,是同学们最认真学习的时候。带着一个模糊的、大概的目标去复习,学生所学的东西会更多。他们会带着自己的理解去猜,去押题:哪些地方是知识点?哪些地方可能考?哪些地方不太容易成为考题?……诸如此类的思考,其实是一种训练和判断。
很多人可能都有这样的经验:认真努力的思考,押对了题,获得了一个高分,那种满足和喜悦,真是畅快无比。这类似于,你做了一个正确的判断,获得了奖励;你做了一个错误的预测,获得了惩罚。因此,我有时候想,一些专科类的学校,老师划了大量的所谓的重点,甚至把题目都透露给学生,这对于学生其实是一种羞辱和机会损失。因为,这些学校的老师,都以为学生们素质差,能力差,就应该给题目划重点才能得到分数;反过来,学生们都以为机械的背题,背重点就可以高分了。因此也失去了一个很好的判断和提升自我认知的机会。因此,我的课程尽量避免划太详细的重点,避免太容易过的考试。我想去维护一个相对公平的评价。
当然,我也无法避免"熟悉者偏差“。对那些我比较熟悉,经常一起讨论交流、经常报告、态度良好的同学,我都愿意帮助他们。可能在潜意识里,每个人都会认为:他们都挺认真的,也很上进,为何不帮帮他们?这对于那些不这么积极、不那么喜欢和人交流的同学,可能是一种不公平。但是,反过来想,这不就是人性吗?人比较喜欢自己熟悉的人,而熟悉的人也更容易成为你的朋友,亘古不变。这些同学展现出来的积极参与、主动交流、好学上进,不也是一种争取的表现吗?这么想,我也就不那么紧张这种熟悉者偏差了。但课程的公平公正,是最基础的底座。
课程的分数对学生很重要。从5年、10年的时间纬度上讲,分数的重要性会慢慢的被抹平,也可能被放大。对一些人来讲,这次的分数低了,不妨碍他们在未来所取得的成就。因为他们有积极的成长性思维,相信任何时候,都可以进步,可以选择更好的机会。对另一些人来讲,这次的分数低了,他便错失了机会,相当于被动的选择了一条道路;而他又无法扭转这个道路,只能朝着依赖的路径越走越远。我希望我教过的同学们,都努力成为前者。
等到了社会,你又发现:显式的考试和考卷很少了,甚至就没有了。但那个时候,才是真正考验你的时候。因为,社会对你的评判和评价无处不在,但不会有老师再给你一个分数了。生活只会给你一些零星,隐隐约约的反馈。你需要做的,是及时的、用心的去收集这些反馈。思考,反省,行动,方能不断进步。