本次介绍从网络嵌入的背景入手,介绍了什么是网络嵌入,网络嵌入的目标。
网络嵌入(Network Embedding)旨在学习网络中节点的低维度潜在表示,所学习到的特征表示可以用作基于图的各种任务的特征,例如分类,聚类,链路预测和可视化。
通过对网络嵌入和图嵌入的对比可以了解到网络嵌入除了现有观测到的网络边之外,还需要进一步考虑网络的高阶结构、网络的性质。
在了解网络嵌入的方法和常用的网络嵌入模型的同时,介绍了LINE算法、DeepWalk算法、Node2vec算法以及SDNE算法等几种较为经典的算法的基本思想和特点。
[报告]
Tue Nov 27 2018 14:38:26 GMT+0800 (中国标准时间)
本次报告主要有以下几个内容:
1.研究背景和意义:信息数据呈现出新的特点,已有技术无法满足要求,数据管理问题日益突出,个人数据空间技术研究具有重要意义。
2.概述:(1)数据空间的提出(2)基本特性 (3)服务模式;
基本概念:(1)非形式化描述 (2)数据项 (3)数据关联 (4)数据空间;
体系框架;
研究现状:(1)研究的问题 (2)相关的会议与期刊 (3)研究小组 (4)国内情况。
3.主要工作:(1)数据空间模型:核心数据空间,任务空间;(2)数据空间构建;(3)数据空间查询:核心数据空间查询,任务空间查询;(4)数据空间原型系统。
4.总结与展望。
[报告]
Sat Nov 24 2018 17:30:01 GMT+0800 (中国标准时间)
networkx是一个处理图结构的python第三方库,提供简洁的API,方便用户画图。
此次报告包含:
1.(基础)networkx常用操作介绍,包括建图、添加结点、添加边,为点和边添加和提取属性。
2.(应用)介绍利用osmium和networkx来处理osm文件,将其结点经纬度数据提取到json文件,将点边关系保存为DIMACS格式(参考http://lcs.ios.ac.cn/~caisw/Resource/about_DIMACS_graph_format.txt)。
更多networkx操作可以参考官网https://networkx.github.io/documentation/stable/tutorial.html。
[报告]
Wed Nov 14 2018 21:30:08 GMT+0800 (中国标准时间)
一、系统目标
仿照RapidMiner的AutoModel模块,并做成Web形式。提供
1. 经典样例数据、
2. 数据导入(从电脑导入/从数据库导入)、
3. 预测分析、
4. 聚类分析、
5. 列选择、
6. 模型选择、
7. 参数自动/手动调整、
8. 结果图表展示
等功能。
二、目前做的
1、服务器搭建完毕,使用flask框架
2、数据导入功能(完成了文件导入,从数据库导入还没做)
3、测试了flask框架中运行pyspark的可行性
三、接下来要做的
1、数据导入(从数据库导入)
2、数据预处理(缺失值等)
3、解决标题问题
4、数据上传之后马上展示出来
四、结合导师建议
研究机器学习工作流(ML Pipelines)、给用户提供一系列选择处理后再run模型。
[报告]
Mon Nov 12 2018 15:42:54 GMT+0800 (中国标准时间)
在目前的城市交通路网中,道路、环境信息成为交通系统中不可或缺的一部分。于是在信息收集中,机会车辆感知这一概念被提了出来。机会车辆感知是利用嵌入在车辆或智能手机中的各种传感器来收集无处不在的数据以进行大规模城市感知的新理念。然而现有的工作缺乏对这种传感系统中覆盖问题的深入研究,例如:
(1)如何定义和测量覆盖?
(2)覆盖质量与车辆数量之间有什么关系?
(3)如何选择最小的车辆数量来达到特定的覆盖质量?等等
而本项目就针对如何高效率的采集数据进行深入研究
[报告]
Mon Nov 05 2018 19:10:46 GMT+0800 (中国标准时间)
目前公交公司主要依靠调度工作人员(总调度和站调员)对在公交排班与实际运营过程中发生的情况做出相应的调整,这种调整主要包括以下两种情况:
第一,排班调整:这是由于在发班前由于驾驶员请假、车辆维修报检造成的车辆不能按计划进行发班所进行的调整。
第二,实时监测与调度:调度工作人员在公交运营当天,实时监测公交线路车辆的运营情况界面,该界面显示了当前线路在当前时段下正在运营的线路车辆的地理位置信息,调度员根据运行车辆分布情况判断是否发生路堵现象,进而根据经验进行排班调整。
但仅依靠调度工作人员凭借经验进行调度存在以下几方面的问题:
首先,调度工作人员未必能及时发现晚点车辆并作出决策;
其次,缺少辅助调度人员进行调度决策的车辆到离站预测工具,使得调度工作人员作出的调度未必合理;
最后,调度人员根据个人经验进行调度,存在主观因素,缺乏合理性和科学性;
因此,开发一套能够辅助调度人员进行科学合理的调度决策智能调度系统就显得尤为重要。
[报告]
Mon Nov 05 2018 19:05:31 GMT+0800 (中国标准时间)
本次报告主要分三个部分介绍:
1.实习期间的工作(数据分析师方向):
(1)产品核心数据监控(日活、周活、月活、留存率、变现相关)
(2)对于业务人员的数据需求
(3)产品发版、运营策略上线后效果分析
(4)产品数据分析
2.数据分析师方向资料推荐:
(1)常用工具:MySQL、Python、Linux、hive、Redis、SSDB、Excel、PHP
(2)推荐书籍:《精益数据分析》、《数据挖掘与数据化运营实战》、《商务与经济统计》
(3)其他书籍:《数据驱动从方法到实践》、《谁说菜鸟不会数据分析》
(4)网站推荐:人人都是产品经理(数据贴)
3.数据岗的三个方向的职业规划与必备技能
(1)市场调研
(2)数据分析/数据挖掘
(3)数据研发
[报告]
Mon Nov 05 2018 15:27:09 GMT+0800 (中国标准时间)
1. 背景介绍
2. 模型描述:Station and Stops,Flex Route,Request,Service Area
3. 工具介绍:neo4j,JGraphT,Cplex,java
4. 实验过程:创建图,调用cplex获取该区间的公车排班表,模拟车在路网上行驶,根据请求到指定地点接送乘客,计算相应的性能指标。
[报告]
Mon Nov 05 2018 14:41:28 GMT+0800 (中国标准时间)
1.简介
借助graphhopper提供的MapMatching项目(https://github.com/graphhopper/map-matching),将其改写成匹配厦门市地图的项目。
2.输入&输出
输入:
厦门市地图 xiamen.osm
和*.gpx 数据;
输出:
地图匹配路段
3.DoWork函数的简要步骤:
(1).过滤过于相近的节点
(2).找到每个点的匹配边
(3).创建一个图表,为这些边创建虚拟节点
(4).删除重复节点(虚拟节点不会被删掉)
(5).从所有GPX条目的查询结果中创建候选项
(6).计算最有可能的候选项
(7).传递返回值
4.维特比算法(计算最有可能的候选项)
隐马尔科夫模型计算转移概率,选择最有可能的候选项。
5.Mapmatching的dowork函数的调用
[报告]
Mon Oct 29 2018 21:02:53 GMT+0800 (中国标准时间)
在交通监控,路线规划等研究中,估算城市中任何路径(由一系列连接的路段表示)的行程时间非常重要。但是,这是一个非常具有挑战性的问题,受到各种复杂因素影响,包括空间相关性,时间依赖性,外部条件(如天气,交通信号灯)。
先前的工作通常侧重于估计各个路段或子路径的行程时间,然后总结这些时间,这导致估计不准确,因为这些方法不考虑复杂交通情况,并且可能累积局部误差。为了解决这些问题,论文中提出了一个端到端的深度学习路径时间估算框架(称为DeepTTE),它直接估算整条路径的消耗时间。更具体地说,论文通过将地理信息集成后,进行地理卷积运算,能够捕获空间相关性。通过在地理卷积层上堆叠循环单元,DeepTTE也可以捕获时间依赖性。在DeepTTE的顶部给出了一个多任务学习组件,它学习在训练阶段同时估计整个路径和每个子路径的传播时间。对两个轨迹数据集的广泛实验表明,DeepTTE显着优于最先进的方法。
[报告]
Tue Oct 23 2018 16:19:12 GMT+0800 (中国标准时间)
该报告内容主要包括:
1.大型路网中电动汽车充电站的平衡配置问题;
2.简要介绍了BLP问题;
3.给出了课题中相关名词的具体定义以及问题的符号化定义;
4.展示了模拟路网中的相关实验步骤。
[报告]
Mon Oct 15 2018 15:25:01 GMT+0800 (中国标准时间)
1.研究背景
2.出租车匹配问题的相关定义
3.Neo4j中路网存储结构的介绍
4.车辆和请求的匹配算法
5.实验设计
[报告]
Tue Oct 09 2018 15:11:37 GMT+0800 (中国标准时间)
1.DeeCamp人工智能训练营简介
2.介绍深度学习
3.优化训练方法的手段
4.神经网络变体
5.前沿技术
[报告]
Tue Oct 09 2018 15:03:23 GMT+0800 (中国标准时间)
**2022届**
曹辉彬,硕士,字节跳动,深圳(2019届本科)
廖林波,硕士,腾讯,深圳
江丽英,硕士,美团,北京
林正男,本科,北京大学,读研
何炫华,本科,中国科学技术大学,读研
王智舟,本科,厦门亿联,厦门
陈世纬,本科,携程集团,上海
**2021届**
杨诗鹏,硕士,百度公司,北京(2018届本科)
孟戈,硕士,厦门大学,读博
苏畅,本科,中科院软件所,保研
王梓,本科,电子科技大学,读研
洪永团,本科,东南大学,读研
张浩宇,本科,波士顿大学,留学
林娜,本科,厦门亿联网络,厦门
刘守宇,本科,拼多多,上海
麦多健,本科,字节跳动,上海
李郑伟,本科,深圳虾皮信息科技,深圳
蔡鹏华,本科,福建烟草局,泉州
**2020届**
徐易凡,硕士,华为杭研所,杭州(2017届本科)
腾威,硕士,花旗银行,上海
罗雅馨,本科,华中科技大学,保研
陶玉娇,本科,厦门建发,厦门
熊安书,本科,未定
**2019届**
张璐,硕士,农业银行成都开发中心,成都
曹辉彬,本科,厦门大学读研
崔少岩,本科,爱丁堡大学读研
崔贺宇,本科,King‘s College London读研
王铭辉,本科,华为杭研所,杭州
赵政宇,本科,华为杭研所,杭州
王寅骅,本科,深圳农商银行,深圳
黄一鑫,本科,厦门网宿科技,厦门
**2018届**
吕铮, 硕士,全国股转公司,北京 (2015届本科)
林志捷,硕士,外企,厦门 (2015届本科)
杨诗鹏,本科,厦门大学读研
林海霖,本科,网宿科技,厦门
黄书胜,本科,招商银行,贵阳
殷子民,本科,厦门航空,厦门
**2017届**
徐易凡,本科,厦门大学读研
周策,本科,浙江大学读研
陈宏东,本科,网宿科技,厦门
**2016届**
待补充
[资料]
Sun Jun 17 2018 07:31:43 GMT+0800 (中国标准时间)
机器学习的热度不减,不断有新的学习材料和教材出现。最近我梳理了一下关于数据分析、机器学习的一些学习材料。这些资料大部分是我看过学过的,觉得很不错。特推荐给感兴趣的同学们。
**书本和原理:**
《机器学习》 周志华
《统计学习方法》 李航
**基础数据:**
Pandas、 Numpy: **(最基础 )**
Python_for_Data_Analysis
Scikit-Learn: **(入门工具使用)**
Scikit-learn Cookbook
Deep Learning / Keras:**(深度学习进阶)**
Deep Learning with Python by François Chollet
**网络资源:**
*深度学习相关*
1) 台湾大学李宏毅 机器学习/深度学习课程
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML17_2.html
国内视频:https://www.bilibili.com/video/av9770302/?from=search&seid=10129090994156472553
https://search.bilibili.com/all?keyword=%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0&from_source=banner_search
2) 吴恩达深度学习课程
https://www.bilibili.com/video/av66314465?from=search&seid=7623799504376444305
3) 邱锡鹏机器学习与深度学习
https://github.com/nndl/nndl.github.io
廖雪峰Python教程:
https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000
目前到的最好的、最细致的**书籍分析、机器学习**在线Tutorial:
https://machinelearningmastery.com/start-here/
**Cheat Sheet:**
https://www.datacamp.com/community/data-science-cheatsheets
以上各种工具,都有快速检索的小抄。方便查询和复习。
[技术]
Mon Apr 02 2018 21:36:16 GMT+0800 (中国标准时间)
近日在写一些代码,用nodejs搭建一个简单的CMS功能的小网站。采用的架构是boostrap+jquery,支持响应式布局。主体功能很快就写好了,难点似乎在前端的设计和交互,特别是前端的设计和编程。对前端框架有点生疏,不时的出现一些问题。随便举几个例子,比如:
> 1. 页面中的一个链接突然无法点击,鼠标放上去,根本没有反应。但检查语法,是正确无误的。而且,仅在宽度为1000多px的时候出问题,在更小的屏幕是可以显示的。这个问题,该如何解决?
> 2. 想调整一个div,使它与窗体之间没有缝隙;“margin-left, padding-left”设置为0,但调整总是无法做到,该如何解决?
> 3. 页面有标题和内容模块,在这两个模块之间需要间隔一段合适的距离;调整了标题所在的titleblock的高度,但还是无法生效,该如何解决?
> 4. 一个div的文字,突然跑到另一div的范围里了,怎么办?
>
> ……
类似的小问题还很多,而且时不时的冒出来。经常一个地方调对了,另一个地方又可能出错了。特别是如果要针对大、中、小屏幕进行适配,则更有出错的可能了。因此,一个小小的界面细节,有时候也需要花费好几个小时来解决。2天下来,终于把界面都调整好,网站达到可以上线的程度了。对于我这个习惯于后端开发的人,发现自己把大量的时间都用于调整和优化界面的时候,还是会冒出一些挫折和纠结的情绪:
> 那么多的时间,仅仅为了一个所谓的“好看一点点”,前端程序员用尽技巧,真的有必要吗?这是所谓的雕虫小技吗?
思索过后,你发现这个小技,对于我们现在其实非常非常重要。首先,目前的软件和服务已经脱离了买方市场的时代,软件层出不穷而且总有替代品。基本的功能大家都有,大家必然往“更好看,更好用”的地方去竞争。因此,这个时代,其实是“小技”发挥重要作用的时代。这也是为何现在大家如此强调“用户体验”的原因了。类似的,日本的一些产品做工都很精细,所有的小细节设计者都几乎考虑到了,因为他们已经度过了粗放型的经济模式,转向精耕细作了。而这,也是我们这个时代软件行业正在经历的阶段。其次,前端与“设计”和“用户体验”密切相关,对人工的需求量巨大。真正好的产品和服务,必然是注入大量的时间、精力和设计元素完成的。远的,大家看看中学时课本讲到的陶瓷、景泰蓝等工艺,那个时间和资源消耗是多少?近的,大家看好莱坞大片的制作过程,好的效果都是一帧一帧抠出来的,工作量和成本又是多少?大家可以温习下关于景泰蓝的制作过程,以及好莱坞大片特效的制作步骤:
> 1. 在每一个点蓝的师傅面前,都由低到高排着一摞白色小碟,里面是掺了水的釉料。细看去,同样是紫色,但从深紫到浅紫,竟然能分出十多种层次来。制作精良的景泰蓝作品,对点蓝要求很高。一片花瓣,要描绘颜色的渐变,就要由深入浅润染几个层次,才能表现出花朵特有的美感——这也是景泰蓝的魅力所在,如果一朵花瓣只涂一二种颜色,功夫省了,景泰蓝之美也消失了。……制胎、掐丝、点蓝烧蓝、磨光和镀金,这就是传统手工艺品景泰蓝的制作的五大主要工序,然而制作景泰蓝的过程要远比这复杂,中间糅杂了多达上百道工序,而这些工序的基石,是设计师的奇思妙想。
>
>
>
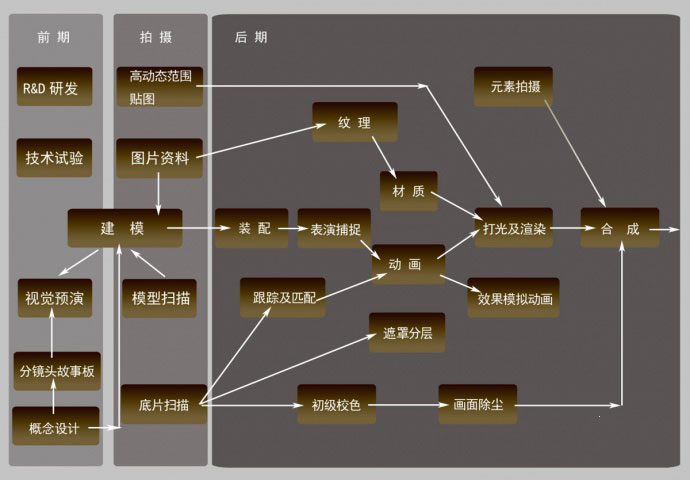
> 2. 动画制作是一个非常繁琐而吃重的工作,分工极为细致。通常分为前期制作、制作、后期制作等。前期制作又包括了企划、作品设定、资金募集等;制作包括了分镜、原画、动画、上色、背景作画、摄影、配音、录音等;后期制作包括合成、剪接、试映等。
>
> 
因此,千万不要觉得在一个网站的几个页面花几天时间是无法接受的事情。其实,好的东西和产品,都是需要大量的时间和人力来喂养的。以后,如果看到一些制作精美、交互优良的界面,请在心里向那些前端开发人员的辛苦付出和努力点个赞吧。
[随笔]
Thu Jan 26 2017 09:29:19 GMT+0800 (中国标准时间)
返回 [Spark MLlib入门教程](http://mocom.xmu.edu.cn/article/show/5858ab782b2730e00d70fa08/0/1)
CountVectorizer和CountVectorizerModel旨在通过计数来将一个文档转换为向量。当不存在先验字典时,Countvectorizer可作为Estimator来提取词汇,并生成一个CountVectorizerModel。该模型产生文档关于词语的稀疏表示,其表示可以传递给其他算法如LDA。
在fitting过程中,countvectorizer将根据语料库中的词频排序从高到低进行选择,词汇表的最大含量由vocabsize参数来指定。一个可选的参数minDF也影响fitting过程,它指定词汇表中的词语至少要在多少个不同文档中出现。
我们接下来通过一个例子来进行介绍。首先,导入CountVectorizer所需要的包:
```scala
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.sql.SQLContext
import org.apache.spark.ml.feature.{CountVectorizer, CountVectorizerModel}
```
接下来,根据SparkContext来创建一个SQLContext,其中sc是一个已经存在的SparkContext;然后导入sqlContext.implicits._来实现RDD到Dataframe的隐式转换。
```scala
scala> val sqlContext = new SQLContext(sc)sqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@225a9fc6
scala> import sqlContext.implicits._
import sqlContext.implicits._
```
假设我们有如下的DataFrame包含id和words两列,一共有两个文档。
```scala
scala> val df = sqlContext.createDataFrame(Seq(
| (0, Array("a", "b", "c")),
| (1, Array("a", "b", "b", "c", "a"))
| )).toDF("id", "words")
df: org.apache.spark.sql.DataFrame = [id: int, words: array]
```
我们创建一个CountVectorizerModel,设定词汇表的最大size为3,设定词汇表中的词至少要在2个文档中出现过。
```scala
scala> val cvModel: CountVectorizerModel = new CountVectorizer().
| setInputCol("words").
| setOutputCol("features").
| setVocabSize(3).
| setMinDF(2).
| fit(df)
cvModel: org.apache.spark.ml.feature.CountVectorizerModel = cntVec_237a080886a2
scala> cvModel.transform(df).select("features").foreach { println }
[(3,[0,1,2],[1.0,1.0,1.0])]
[(3,[0,1,2],[2.0,2.0,1.0])]
```
从打印结果我们可以看到,词汇表中有“a”,“b”,“c”三个词,且这三个词都在2个文档中出现过。其中结果中前面的3代表的是vocabsize;“a”和“b”都出现了3次,而“c”出现两次,所以在结果中0和1代表“a”和“b”,2代表“c”;后面的数组是相应词语在各个文档中出现次数的统计。倘若把vocabsize设为2,则不会出现“c”。
也可以用下面的方式来创建一个CountVectorizerModel,通过指定一个数组来预定义一个词汇表,在本例中即只包含“a”,“b”,“c”三个词。
```scala
scala> val cvm = new CountVectorizerModel(Array("a", "b", "c")).
| setInputCol("words").
| setOutputCol("features")
cvm: org.apache.spark.ml.feature.CountVectorizerModel = cntVecModel_c6a17c2befee
scala> cvm.transform(df).select("features").foreach { println }
[(3,[0,1,2],[1.0,1.0,1.0])]
[(3,[0,1,2],[2.0,2.0,1.0])]
```
[技术]
Wed Jan 18 2017 15:29:56 GMT+0800 (中国标准时间)
返回 [Spark MLlib入门教程](http://mocom.xmu.edu.cn/article/show/5858ab782b2730e00d70fa08/0/1)
Spark的机器学习处理过程中,经常需要把标签数据(一般是字符串)转化成整数索引,而在计算结束又需要把整数索引还原为标签。这就涉及到几个转换器:StringIndexer、 IndexToString,OneHotEncoder,以及针对类别特征的索引VectorIndexer。
## StringIndexer
StringIndexer是指把一组字符型标签编码成一组标签索引,索引的范围为0到标签数量,索引构建的顺序为标签的频率,优先编码频率较大的标签,所以出现频率最高的标签为0号。如果输入的是数值型的,我们会把它转化成字符型,然后再对其进行编码。在pipeline组件,比如Estimator和Transformer中,想要用到字符串索引的标签的话,我们一般需要通过setInputCol来设置输入列。另外,有的时候我们通过一个数据集构建了一个StringIndexer,然后准备把它应用到另一个数据集上的时候,会遇到新数据集中有一些没有在前一个数据集中出现的标签,这时候一般有两种策略来处理:第一种是抛出一个异常(默认情况下),第二种是通过掉用 setHandleInvalid("skip")来彻底忽略包含这类标签的行。
```scala
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.sql.SQLContext
import org.apache.spark.ml.feature.StringIndexer
scala> val sqlContext = new SQLContext(sc)
sqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@2869d920
scala> import sqlContext.implicits._
import sqlContext.implicits._
scala> val df1 = sqlContext.createDataFrame(
| Seq((0, "a"), (1, "b"), (2, "c"), (3, "a"), (4, "a"), (5, "c"))
| ).toDF("id", "category")
df1: org.apache.spark.sql.DataFrame = [id: int, category: string]
scala> val indexer = new StringIndexer().
| setInputCol("category").
| setOutputCol("categoryIndex")
indexer: org.apache.spark.ml.feature.StringIndexer = strIdx_95a0a5afdb8b
scala> val indexed1 = indexer.fit(df1).transform(df1)
indexed1: org.apache.spark.sql.DataFrame = [id: int, category: string, categoryIndex: double]
scala> indexed1.show()
+---+--------+-------------+
| id|category|categoryIndex|
+---+--------+-------------+
| 0| a| 0.0|
| 1| b| 2.0|
| 2| c| 1.0|
| 3| a| 0.0|
| 4| a| 0.0|
| 5| c| 1.0|
+---+--------+-------------+
scala> val df2 = sqlContext.createDataFrame(
| Seq((0, "a"), (1, "b"), (2, "c"), (3, "a"), (4, "a"), (5, "d"))
| ).toDF("id", "category")
df2: org.apache.spark.sql.DataFrame = [id: int, category: string]
scala> val indexed2 = indexer.fit(df1).setHandleInvalid("skip").transform(df2)
indexed2: org.apache.spark.sql.DataFrame = [id: int, category: string, categoryIndex: double]
scala> indexed2.show()
+---+--------+-------------+
| id|category|categoryIndex|
+---+--------+-------------+
| 0| a| 0.0|
| 1| b| 2.0|
| 2| c| 1.0|
| 3| a| 0.0|
| 4| a| 0.0|
+---+--------+-------------+
scala> val indexed3 = indexer.fit(df1)transform(df2)
indexed3: org.apache.spark.sql.DataFrame = [id: int, category: string, categoryIndex: double]
scala> indexed3.show()
org.apache.spark.SparkException: Unseen label: d.
```
在上例当中,我们首先构建了1个dataframe,然后设置了StringIndexer的输入列和输出列的名字。通过indexed1.show(),我们可以看到,StringIndexer依次按照出现频率的高低,把字符标签进行了排序,即出现最多的“a”被编号成0,“c”为1,出现最少的“b”为0。接下来,我们构建了一个新的dataframe,这个dataframe中有一个再上一个dataframe中未曾出现的标签“d”,然后我们通过设置setHandleInvalid("skip")来忽略标签“d”的行,结果通过indexed2.show()可以看到,含有标签“d”的行并没有出现。如果,我们没有设置的话,则会抛出异常,报出“Unseen label: d”的错误。
## IndexToString
对称的,IndexToString的作用是把标签索引的一列重新映射回原有的字符型标签。一般都是和StringIndexer配合,先用StringIndexer转化成标签索引,进行模型训练,然后在预测标签的时候再把标签索引转化成原有的字符标签。当然,也允许你使用自己提供的标签。
```scala
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.sql.SQLContext
import org.apache.spark.ml.feature.{StringIndexer, IndexToString}
scala> val sqlContext = new SQLContext(sc)
sqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@2869d920
scala> import sqlContext.implicits._
import sqlContext.implicits._
scala> val df = sqlContext.createDataFrame(Seq(
| (0, "a"),
| (1, "b"),
| (2, "c"),
| (3, "a"),
| (4, "a"),
| (5, "c")
| )).toDF("id", "category")
df: org.apache.spark.sql.DataFrame = [id: int, category: string]
scala> val indexer = new StringIndexer().
| setInputCol("category").
| setOutputCol("categoryIndex").
| fit(df)
indexer: org.apache.spark.ml.feature.StringIndexerModel = strIdx_00fde0fe64d0
scala> val indexed = indexer.transform(df)
indexed: org.apache.spark.sql.DataFrame = [id: int, category: string, categoryIndex: double]
scala> val converter = new IndexToString().
| setInputCol("categoryIndex").
| setOutputCol("originalCategory")
converter: org.apache.spark.ml.feature.IndexToString = idxToStr_b95208a0e7ac
scala> val converted = converter.transform(indexed)
converted: org.apache.spark.sql.DataFrame = [id: int, category: string, categoryIndex: double, originalCategory: string]
scala> converted.select("id", "originalCategory").show()
+---+----------------+
| id|originalCategory|
+---+----------------+
| 0| a|
| 1| b|
| 2| c|
| 3| a|
| 4| a|
| 5| c|
+---+----------------+
```
在上例中,我们首先用StringIndexer读取数据集中的“category”列,把字符型标签转化成标签索引,然后输出到“categoryIndex”列上。然后再用IndexToString读取“categoryIndex”上的标签索引,获得原有数据集的字符型标签,然后再输出到“originalCategory”列上。最后,通过输出“originalCategory”列,可以看到数据集中原有的字符标签。
## OneHotEncoder
独热编码是指把一列标签索引映射成一列二进制数组,且最多的时候只有一位有效。这种编码适合一些期望类别特征为连续特征的算法,比如说逻辑斯蒂回归。
```scala
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.sql.SQLContext
import org.apache.spark.ml.feature.{OneHotEncoder, StringIndexer}
scala> val sqlContext = new SQLContext(sc)
sqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@2869d920
scala> import sqlContext.implicits._
import sqlContext.implicits._
scala> val df = sqlContext.createDataFrame(Seq(
| (0, "a"),
| (1, "b"),
| (2, "c"),
| (3, "a"),
| (4, "a"),
| (5, "c"),
| (6, "d"),
| (7, "d"),
| (8, "d"),
| (9, "d"),
| (10, "e"),
| (11, "e"),
| (12, "e"),
| (13, "e"),
| (14, "e")
| )).toDF("id", "category")
df: org.apache.spark.sql.DataFrame = [id: int, category: string]
scala> val indexer = new StringIndexer().
| setInputCol("category").
| setOutputCol("categoryIndex").
| fit(df)
indexer: org.apache.spark.ml.feature.StringIndexerModel = strIdx_b315cf21d22d
scala> val indexed = indexer.transform(df)
indexed: org.apache.spark.sql.DataFrame = [id: int, category: string, categoryIndex: double]
scala> val encoder = new OneHotEncoder().
| setInputCol("categoryIndex").
| setOutputCol("categoryVec")
encoder: org.apache.spark.ml.feature.OneHotEncoder = oneHot_bbf16821b33a
scala> val encoded = encoder.transform(indexed)
encoded: org.apache.spark.sql.DataFrame = [id: int, category: string, categoryIndex: double, categoryVec: vector]
scala> encoded.show()
+---+--------+-------------+-------------+
| id|category|categoryIndex| categoryVec|
+---+--------+-------------+-------------+
| 0| a| 2.0|(4,[2],[1.0])|
| 1| b| 4.0| (4,[],[])|
| 2| c| 3.0|(4,[3],[1.0])|
| 3| a| 2.0|(4,[2],[1.0])|
| 4| a| 2.0|(4,[2],[1.0])|
| 5| c| 3.0|(4,[3],[1.0])|
| 6| d| 1.0|(4,[1],[1.0])|
| 7| d| 1.0|(4,[1],[1.0])|
| 8| d| 1.0|(4,[1],[1.0])|
| 9| d| 1.0|(4,[1],[1.0])|
| 10| e| 0.0|(4,[0],[1.0])|
| 11| e| 0.0|(4,[0],[1.0])|
| 12| e| 0.0|(4,[0],[1.0])|
| 13| e| 0.0|(4,[0],[1.0])|
| 14| e| 0.0|(4,[0],[1.0])|
+---+--------+-------------+-------------+
```
在上例中,我们构建了一个dataframe,包含“a”,“b”,“c”,“d”,“e” 五个标签,通过调用OneHotEncoder,我们发现出现频率最高的标签“e”被编码成第0位为1,即第0位有效,出现频率第二高的标签“d”被编码成第1位有效,依次类推,“a”和“c”也被相继编码,出现频率最小的标签“b”被编码成全0。
## VectorIndexer
VectorIndexer解决向量数据集中的类别特征索引。它可以自动识别哪些特征是类别型的,并且将原始值转换为类别索引。它的处理流程如下:
1.获得一个向量类型的输入以及maxCategories参数。
2.基于不同特征值的数量来识别哪些特征需要被类别化,其中最多maxCategories个特征需要被类别化。
3.对于每一个类别特征计算0-based(从0开始)类别索引。
4.对类别特征进行索引然后将原始特征值转换为索引。
索引后的类别特征可以帮助决策树等算法恰当的处理类别型特征,并得到较好结果。
在下面的例子中,我们读入一个数据集,然后使用VectorIndexer来决定哪些特征需要被作为类别特征,将类别特征转换为他们的索引。
```scala
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.sql.SQLContext
import org.apache.spark.ml.feature.VectorIndexer
import org.apache.spark.mllib.linalg.{Vector, Vectors}
scala> val sqlContext = new SQLContext(sc)
sqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@2869d920
scala> import sqlContext.implicits._
import sqlContext.implicits._
scala> val data = Seq(Vectors.dense(-1.0, 1.0, 1.0),Vectors.dense(-1.0, 3.0, 1.0), Vectors.dense(0.0, 5.0, 1.0))
data: Seq[org.apache.spark.mllib.linalg.Vector] = List([-1.0,1.0,1.0], [-1.0,3.0,1.0], [0.0,5.0,1.0])
scala> val df = sqlContext.createDataFrame(data.map(Tuple1.apply)).toDF("features")
df: org.apache.spark.sql.DataFrame = [features: vector]
scala> val indexer = new VectorIndexer().
| setInputCol("features").
| setOutputCol("indexed").
| setMaxCategories(2)
indexer: org.apache.spark.ml.feature.VectorIndexer = vecIdx_abee81bafba8
scala> val indexerModel = indexer.fit(df)
indexerModel: org.apache.spark.ml.feature.VectorIndexerModel = vecIdx_abee81bafba8
scala> val categoricalFeatures: Set[Int] = indexerModel.categoryMaps.keys.toSet
categoricalFeatures: Set[Int] = Set(0, 2)
scala> println(s"Chose ${categoricalFeatures.size} categorical features: " + categoricalFeatures.mkString(", "))
Chose 2 categorical features: 0, 2
scala> val indexedData = indexerModel.transform(df)
indexedData: org.apache.spark.sql.DataFrame = [features: vector, indexed: vector]
scala> indexedData.foreach { println }
[[-1.0,1.0,1.0],[1.0,1.0,0.0]]
[[-1.0,3.0,1.0],[1.0,3.0,0.0]]
[[0.0,5.0,1.0],[0.0,5.0,0.0]]
```
从上例可以看到,我们设置maxCategories为2,即只有种类小于2的特征才被认为是类别型特征,否则被认为是连续型特征。其中类别型特征将被进行编号索引,为了索引的稳定性,规定如果这个特征值为0,则一定会被编号成0,这样可以保证向量的稀疏度(未来还会再维持索引的稳定性上做更多的工作,比如如果某个特征类别化后只有一个特征,则会进行警告等等,这里就不过多介绍了)。于是,我们可以看到第0类和第2类的特征由于种类数不超过2,被划分成类别型特征,并进行了索引,且为0的特征值也被编号成了0号。
[技术]
Wed Jan 18 2017 14:57:34 GMT+0800 (中国标准时间)
返回 [Spark MLlib入门教程](http://mocom.xmu.edu.cn/article/show/5858ab782b2730e00d70fa08/0/1)
Word2Vec 是一种著名的 **词嵌入(Word Embedding)** 方法,它可以计算每个单词在其给定语料库环境下的 **分布式词向量**(Distributed Representation,亦直接被称为词向量)。词向量表示可以在一定程度上刻画每个单词的语义。如果词的语义相近,它们的词向量在向量空间中也相互接近,这使得词语的向量化建模更加精确,可以改善现有方法并提高鲁棒性。词向量已被证明在许多自然语言处理问题,如:机器翻译,标注问题,实体识别等问题中具有非常重要的作用。
Word2vec是一个Estimator,它采用一系列代表文档的词语来训练word2vecmodel。该模型将每个词语映射到一个固定大小的向量。word2vecmodel使用文档中每个词语的平均数来将文档转换为向量,然后这个向量可以作为预测的特征,来计算文档相似度计算等等。
Word2Vec具有两种模型,其一是 **CBOW** ,其思想是通过每个词的上下文窗口词词向量来预测中心词的词向量。其二是 **Skip-gram**,其思想是通过每个中心词来预测其上下文窗口词,并根据预测结果来修正中心词的词向量。两种方法示意图如下图所示:
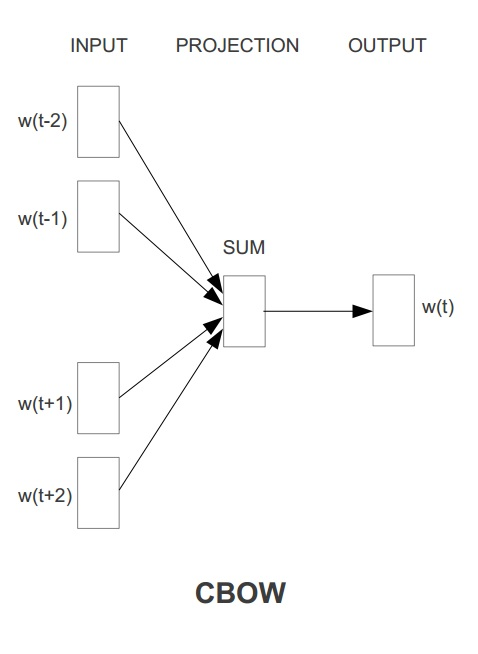
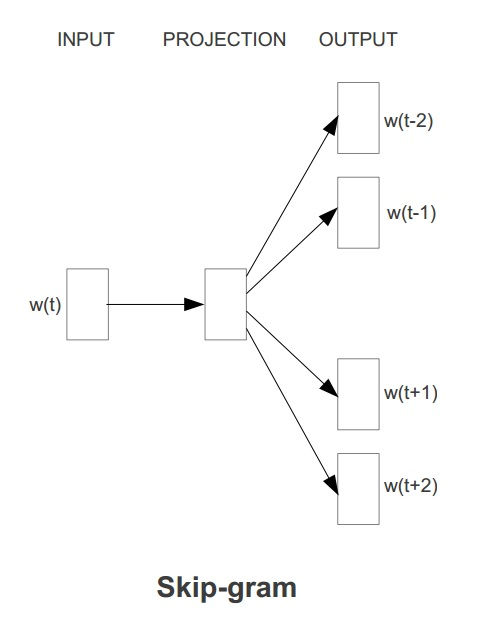
在`ml`库中,Word2vec 的实现使用的是skip-gram模型。Skip-gram的训练目标是学习词表征向量分布,其优化目标是在给定中心词的词向量的情况下,最大化以下似然函数:
$$
\frac{1}{T} \sum_{t=1}^{T} \sum_{j=-k}^{j=k} log{p(w_{t+j}|w_t)}
$$
其中,$w_1$ .... $w_t$ 是一系列词序列,这里 $w_t$ 代表中心词,而 $w_{t+j} (j \in [-k,k])$ 是上下文窗口中的词。
这里,每一个上下文窗口词 $w_i$ 在给定中心词 $w_j$ 下的条件概率由类似 **Softmax** 函数(相当于Sigmoid函数的高维扩展版)的形式进行计算,如下式所示,其中 $u_w$ 和 $v_w$ 分别代表当前词的词向量以及当前上下文的词向量表示:
$$p(w_i|w_j) = \frac{exp(u_{w_i}^{T}v_{w_j})}{ \sum_{l=1}^{V}{exp(u_l^Tv_{w_j})}}$$
因为Skip-gram模型使用的softmax计算较为复杂,所以,`ml`与其他经典的Word2Vec实现采用了相同的策略,使用Huffman树来进行 **层次Softmax(Hierachical Softmax)** 方法来进行优化,使得 $\log{p(w_i|w_j)}$ 计算的复杂度从 $O(V)$ 下降到 $O(log(V))$。
在下面的代码段中,我们首先用一组文档,其中一个词语序列代表一个文档。对于每一个文档,我们将其转换为一个特征向量。此特征向量可以被传递到一个学习算法。
首先,导入Word2Vec所需要的包:
```scala
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.sql.SQLContext
import org.apache.spark.ml.feature.Word2Vec
```
接下来,根据SparkContext来创建一个SQLContext,其中sc是一个已经存在的SparkContext;然后导入sqlContext.implicits._来实现RDD到Dataframe的隐式转换。
```scala
scala> val sqlContext = new SQLContext(sc)
sqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@225a9fc6
scala> import sqlContext.implicits._
import sqlContext.implicits._
```
然后,创建三个词语序列,每个代表一个文档。
```scala
scala> val documentDF = sqlContext.createDataFrame(Seq(
| "Hi I heard about Spark".split(" "),
| "I wish Java could use case classes".split(" "),
| "Logistic regression models are neat".split(" ")
| ).map(Tuple1.apply)).toDF("text")
documentDF: org.apache.spark.sql.DataFrame = [text: array]
```
新建一个Word2Vec,设置相应的参数,这里设置特征向量的维度为3。具体的参数描述可以参见http://spark.apache.org/docs/1.6.2/api/scala/index.html#org.apache.spark.ml.feature.Word2Vec。
```
scala> val word2Vec = new Word2Vec().
| setInputCol("text").
| setOutputCol("result").
| setVectorSize(3).
| setMinCount(0)
word2Vec: org.apache.spark.ml.feature.Word2Vec = w2v_e2d5128ba199
```
读入训练数据,用fit()方法生成一个Word2VecModel。
```scala
scala> val model = word2Vec.fit(documentDF)
model: org.apache.spark.ml.feature.Word2VecModel = w2v_e2d5128ba199
```
利用Word2VecModel把文档转变成特征向量。
```scala
scala> val result = model.transform(documentDF)
result: org.apache.spark.sql.DataFrame = [text: array, result: vector]
scala> result.select("result").take(3).foreach(println)
[[0.018490654602646827,-0.016248732805252075,0.04528368394821883]]
[[0.05958533100783825,0.023424440695505054,-0.027310076036623544]]
[[-0.011055880039930344,0.020988055132329465,0.042608972638845444]]
```
我们可以看到文档被转变为了一个3维的特征向量,这些特征向量就可以被应用到相关的机器学习方法中。
[技术]
Wed Jan 18 2017 14:50:39 GMT+0800 (中国标准时间)
返回 [Spark MLlib入门教程](http://mocom.xmu.edu.cn/article/show/5858ab782b2730e00d70fa08/0/1)
---
**聚类(Clustering)** 是机器学习中一类重要的方法。其主要思想使用样本的不同特征属性,根据某一给定的相似度度量方式(如欧式距离)找到相似的样本,并根据距离将样本划分成不同的组。聚类属于典型的**无监督学习(Unsupervised Learning)** 方法。与监督学习(如分类器)相比[^1],无监督学习的训练集没有人为标注的结果。在非监督式学习中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。
较权威的聚类问题的定义是:
> 所谓聚类问题,就是给定一个元素集合D,其中每个元素具有n个可观察属性,使用某种算法将D划分成k个子集,要求每个子集内部的元素之间相异度尽可能低,而不同子集的元素相异度尽可能高。其中每个子集叫做一个簇。
聚类分析以相似性为基础,其目标是使同一类对象的相似度尽可能地大,不同类对象之间的相似度尽可能地小。换句话说,在一个聚类中的模式之间比不在同一聚类中的模式之间具有更多的相似性。
目前聚类的方法很多,很难对聚类方法提出一个简洁的分类,因为这些类别可能重叠,从而使得一种方法具有几类的特征。但根据基本思想的不同,聚类分析计算方法主要有如下几种:划分算法、层次算法、密度算法、图论聚类法、网格算法和模型算法等。聚类方法已经被广泛运用在如图像处理、客户精准营销、生物信息学等多个领域,也可以作为使用分类方法前对数据进行预先探索的一种手段来使用。
Spark的MLlib库提供了许多可用的聚类方法的实现,如 **KMeans**、**高斯混合模型**、**Power Iteration Clustering(PIC)**、**隐狄利克雷分布(LDA)** 以及 **KMeans** 方法的变种 **二分KMeans(Bisecting KMeans)** 和 **流式KMeans(Streaming KMeans)**等。
## 一、KMeans原理
**KMeans** 是一个迭代求解的聚类算法,其属于 **划分(Partitioning)** 型的聚类方法,即首先创建K个划分,然后迭代地将样本从一个划分转移到另一个划分来改善最终聚类的质量,**KMeans** 的过程大致如下:
```
1.根据给定的k值,选取k个样本点作为初始划分中心;
2.计算所有样本点到每一个划分中心的距离,并将所有样本点划分到距离最近的划分中心;
3.计算每个划分中样本点的平均值,将其作为新的中心;
循环进行2~3步直至达到最大迭代次数,或划分中心的变化小于某一预定义阈值
```
显然,初始划分中心的选取在很大程度上决定了最终聚类的质量,MLlib内置的`KMeans`类提供了名为 **KMeans||** 的初始划分中心选择方法,它是著名的 **KMeans++** 方法的并行化版本,其思想是令初始聚类中心尽可能的互相远离,具体实现细节可以参见斯坦福大学的B Bahmani在PVLDB上的论文[Scalable K-Means++](http://theory.stanford.edu/~sergei/papers/vldb12-kmpar.pdf),这里不再赘述。
## 二、数据集的读取
本文使用模式识别领域广泛使用的UCI数据集中的鸢尾花数据Iris进行实验,它可以在[这里](http://archive.ics.uci.edu/ml/datasets/Iris)获取,Iris数据的样本容量为150,有四个实数值的特征,分别代表花朵四个部位的尺寸,以及该样本对应鸢尾花的亚种类型(共有3种亚种类型)
,如下所示:
```
5.1,3.5,1.4,0.2,setosa
...
5.4,3.0,4.5,1.5,versicolor
...
7.1,3.0,5.9,2.1,virginica
...
```
可以通过`SparkContext`自带的`textFile(..)`方法将文件读入,并进行转换,形成一个`RDD`,如下所示(假设代码在Spark-shell中运行,Spark-shell已自动创建了名为`sc`的`SparkContext`变量,下同):
```scala
//引入相应的包,下文不再引入
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.clustering.{KMeans, KMeansModel}
//读入文件
scala> val rawData = sc.textFile("iris.csv")
rawData: org.apache.spark.rdd.RDD[String] = iris.csv MapPartitionsRDD[48] at textFile at :33
//将RDD[String]转换为RDD[Vector]
scala> val trainingData = rawData.map(line => {Vectors.dense(line.split(",").filter(p => p.matches("\\d*(\\.?)\\d*")).map(_.toDouble))}).cache()
trainingData: org.apache.spark.rdd.RDD[org.apache.spark.mllib.linalg.Vector] = MapPartitionsRDD[49] at map at :35
```
这里我们对RDD使用了filter算子,并通过正则表达式将鸢尾花的类标签过滤掉,Scala语言的正则表达式语法与Java语言类似,正则表达式`\\d*(\\.?)\\d*`可以用于匹配实数类型的数字,`\\d*`使用了`*`限定符,表示匹配0次或多次的数字字符,`\\.?`使用了`?`限定符,表示匹配0次或1次的小数点,关于正则表达式的更多知识,可以自行查阅相关资料,这里不再叙述。
## 三、模型训练与分析
可以通过创建一个`KMeans`类并调用其`run(RDD[Vector])`方法来训练一个KMeans模型`KMeansModel`,在该方法调用前需要设置一系列参数,如下表所示:
| 参数 | 含义 |
| ------------------- | :---------------------: |
| K | 聚类数目,默认为2 |
| maxIterations | 最大迭代次数,默认为20 |
| initializationMode | 初始化模式,默认为"k-means\|\|" |
| runs | 运行次数,默认为:1 |
| initializationSteps | 初始化步数,用于KMeans\|\|,默认为5 |
| epsilon | 迭代停止的阈值,默认为1e-4 |
其中,每一个参数均可通过名为`setXXX(...)`(如maxIterations即为`setMaxIterations()`)的方法进行设置。
由于`KMeans`类只有无参的构造函数,其对象创建、参数设置需要分别进行,且往往使用的只有存放模型的`KMeansModel`类对象,花功夫创建出的`KMeans`类自象本身却并未使用。故MLlib也提供了包装好的高层次方法`KMeans.train(...)`,传入训练样本和相应的参数,即返回一个训练好的`KMeansModel`对象,十分方便。
该方法有4个重载形式,分别可以指定不同的输入参数,具体可以查阅MLlib的API文档,这里我们使用`KMeans.train(data, k, maxIterations, runs)`形式,只需要输入k值、最大迭代次数和运行次数,其他参数使用默认值,如下所示:
```scala
//调用KMeans.train训练模型,指定k值为3,最大迭代100次,运行5次
scala> val model : KMeansModel = KMeans.train(trainingData, 3, 100, 5)
model: org.apache.spark.mllib.clustering.KMeansModel = org.apache.spark.mllib.clustering.KMeansModel@4e4dcf7c
```
*(细节:若iris.csv没有位于当前用户目录下,前面的rawData和trainingData对象都可以成功创建,执行到这一步时才会出现错误,这是因为RDD的transformation操作采用了懒加载策略,只有当action型的操作发生时,才会有实际的计算)*
这样,模型即创建成功了。可以通过`KMeansModel`类自带的`clusterCenters`属性获取到模型的所有聚类中心情况:
```scala
scala> model.clusterCenters.foreach(
| center => {
| println("Clustering Center:"+center)
| })
Clustering Center:[6.314583333333331,2.895833333333334,4.973958333333334,1.7031249999999996]
Clustering Center:[5.19375,3.6312499999999996,1.4749999999999999,0.2718749999999999]
Clustering Center:[4.7318181818181815,2.9272727272727277,1.7727272727272727,0.35000000000000003]
```
也可以通过`predict()`方法来确定每个样本所属的聚类:
```scala
scala> trainingData.collect().foreach(
| sample => {
| val predictedCluster = model.predict(sample)
| println(sample.toString + " belongs to cluster " + predictedCluster)
| })
[5.1,3.5,1.4,0.2] belongs to cluster 1
[4.9,3.0,1.4,0.2] belongs to cluster 1
[4.7,3.2,1.3,0.2] belongs to cluster 1
[4.6,3.1,1.5,0.2] belongs to cluster 1
[5.0,3.6,1.4,0.2] belongs to cluster 1
[5.4,3.9,1.7,0.4] belongs to cluster 1
[4.6,3.4,1.4,0.3] belongs to cluster 1
.....
```
同时,`KMeansModel`类还提供了计算 **集合内误差平方和(Within Set Sum of Squared Error, WSSSE)** 的方法来度量聚类的有效性:
```scala
scala> val wssse = model.computeCost(trainingData)
wssse: Double = 78.85144142614642
```
对于那些无法预先知道K值的情况(本文中使用的Iris数据集很明确其K值为3),可以通过 **WSSSE** 的计算构建出 **K-WSSSE** 间的相关关系,从而确定K的值,一般来说,最优的K值即是 **K-WSSSE** 曲线的 **拐点(Elbow)** 位置(当然,对于某些情况来说,我们还需要考虑K值的语义可解释性,而不仅仅是教条地参考WSSSE曲线)。
[^1]: 此外还有半监督学习( Semi-supervised Learning ),是介于监督学习与无监督学习之间一种机器学习方式,是模式识别和机器学习领域研究的重点问题。
[技术]
Thu Jan 05 2017 15:13:32 GMT+0800 (中国标准时间)
返回 [Spark MLlib入门教程](http://mocom.xmu.edu.cn/article/show/5858ab782b2730e00d70fa08/0/1)
## 一、方法简介
协同过滤是一种基于一组兴趣相同的用户或项目进行的推荐,它根据邻居用户(与目标用户兴趣相似的用户)的偏好信息产生对目标用户的推荐列表。关于协同过滤的一个经典的例子就是看电影。如果你不知道哪一部电影是自己喜欢的或者评分比较高的,那么通常的做法就是问问周围的朋友,看看最近有什么好的电影推荐。而在问的时候,肯定都习惯于问跟自己口味差不多的朋友,这就是协同过滤的核心思想。因此,协同过滤是在海量数据中挖掘出小部分与你品味类似的用户,在协同过滤中,这些用户成为邻居,然后根据他们喜欢的东西组织成一个排序的目录推荐给你(如下图所示)。

协同过滤算法主要分为基于用户的协同过滤算法和基于项目的协同过滤算法。MLlib当前支持基于模型的协同过滤,其中用户和商品通过一小组隐语义因子进行表达,并且这些因子也用于预测缺失的元素。Spark MLlib实现了 [交替最小二乘法](http://dl.acm.org/citation.cfm?id=1608614) (ALS) 来学习这些隐性语义因子。
## 二、隐性反馈 vs 显性反馈
显性反馈行为包括用户明确表示对物品喜好的行为,隐性反馈行为指的是那些不能明确反应用户喜好的行为。在许多的现实生活中的很多场景中,我们常常只能接触到隐性的反馈,例如页面游览,点击,购买,喜欢,分享等等。
基于矩阵分解的协同过滤的标准方法,一般将用户商品矩阵中的元素作为用户对商品的显性偏好。在 MLlib 中所用到的处理这种数据的方法来源于文献: [Collaborative Filtering for Implicit Feedback Datasets](http://dx.doi.org/10.1109/ICDM.2008.22) 。 本质上,这个方法将数据作为二元偏好值和偏好强度的一个结合,而不是对评分矩阵直接进行建模。因此,评价就不是与用户对商品的显性评分,而是与所观察到的用户偏好强度关联起来。然后,这个模型将尝试找到隐语义因子来预估一个用户对一个商品的偏好。
## 三、示例
下面代码读取spark的示例文件,文件中每一行包括一个用户id、商品id和评分。我们使用默认的`ALS.train()` 方法来构建推荐模型并评估模型的均方差。
### 1. 导入需要的包:
```scala
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.mllib.recommendation.ALS
import org.apache.spark.mllib.recommendation.MatrixFactorizationModel
import org.apache.spark.mllib.recommendation.Rating
```
### 2. 读取数据:
首先,读取文本文件,把数据转化成rating类型,即[Int, Int, Double]的RDD;
```scala
scala> val data = sc.textFile("../data/mllib/als/test.data")
data: org.apache.spark.rdd.RDD[String] = ../data/mllib/als/test.data MapPartitio
nsRDD[1] at textFile at :21
scala> val ratings = data.map(_.split(',') match { case Array(user, item, rate)
=> Rating(user.toInt, item.toInt, rate.toDouble)})
ratings: org.apache.spark.rdd.RDD[org.apache.spark.mllib.recommendation.Rating]
= MapPartitionsRDD[2] at map at :26
```
可以把数据打印出来看一下:
```scala
scala> ratings.foreach{x => println(x)}
Rating(1,1,5.0)
Rating(3,2,5.0)
Rating(1,2,1.0)
Rating(3,3,1.0)
Rating(1,3,5.0)
Rating(3,4,5.0)
Rating(1,4,1.0)
Rating(4,1,1.0)
Rating(2,1,5.0)
Rating(4,2,5.0)
Rating(2,2,1.0)
Rating(4,3,1.0)
Rating(2,3,5.0)
Rating(4,4,5.0)
Rating(2,4,1.0)
Rating(3,1,1.0)
```
其中Rating中的第一个int是user编号,第二个int是item编号,最后的double是user对item的评分。
### 3. 构建模型
划分训练集和测试集,比例分别是0.8和0.2。
```scala
scala> val splits = ratings.randomSplit(Array(0.8, 0.2))
splits: Array[org.apache.spark.rdd.RDD[org.apache.spark.mllib.recommendation.Rati
ng]] = Array(MapPartitionsRDD[5] at randomSplit at :30, MapPartitionsRD
D[6] at randomSplit at :30)
scala> val training = splits(0)
training: org.apache.spark.rdd.RDD[org.apache.spark.mllib.recommendation.Rating]
= MapPartitionsRDD[5] at randomSplit at :30
scala> val test = splits(1)
test: org.apache.spark.rdd.RDD[org.apache.spark.mllib.recommendation.Rating] = M
apPartitionsRDD[6] at randomSplit at :30
```
指定参数值,然后使用ALS训练数据建立推荐模型:
```scala
scala> val rank = 10
rank: Int = 10
scala> val numIterations = 10
numIterations: Int = 10
scala> val model = ALS.train(training, rank, numIterations, 0.01)
model: org.apache.spark.mllib.recommendation.MatrixFactorizationModel = org.apac
he.spark.mllib.recommendation.MatrixFactorizationModel@1f14d4a
```
在 MLlib 中的实现有如下的参数:
- `numBlocks` 是用于并行化计算的分块个数 (设置为-1,为自动配置)。
- `rank` 是模型中隐语义因子的个数。
- `iterations` 是迭代的次数。
- `lambda` 是ALS的正则化参数。
- `implicitPrefs` 决定了是用显性反馈ALS的版本还是用适用隐性反馈数据集的版本。
- `alpha` 是一个针对于隐性反馈 ALS 版本的参数,这个参数决定了偏好行为强度的基准。
可以调整这些参数,不断优化结果,使均方差变小。比如:iterations越多,lambda较小,均方差会较小,推荐结果较优。上面的例子中调用了 ALS.train(ratings, rank, numIterations, 0.01) ,我们还可以设置其他参数,调用方式如下:
```scala
val model = new ALS()
.setRank(params.rank)
.setIterations(params.numIterations)
.setLambda(params.lambda)
.setImplicitPrefs(params.implicitPrefs)
.setUserBlocks(params.numUserBlocks)
.setProductBlocks(params.numProductBlocks)
.run(training)
```
### 4. 利用模型进行预测
从 test训练集中获得只包含用户和商品的数据集 :
```scala
scala> val testUsersProducts = test.map { case Rating(user, product, rate) =>
| (user, product)
| }
usersProducts: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[3868] at
map at :34
```
使用训练好的推荐模型对用户商品进行预测评分,得到预测评分的数据集:
```scala
scala> val predictions =
| model.predict(testUsersProducts).map { case Rating(user, product, rate)
| =>((user, product), rate)
| }
predictions: org.apache.spark.rdd.RDD[((Int, Int), Double)] = MapPartitionsRDD[3
877] at map at :45
```
将真实评分数据集与预测评分数据集进行合并。这里,Join操作类似于SQL的inner join操作,返回结果是前面和后面集合中配对成功的,过滤掉关联不上的。
```scala
scala> val ratesAndPreds = test.map { case Rating(user, product, rate) =>
| ((user, product), rate)
| }.join(predictions)
ratesAndPreds: org.apache.spark.rdd.RDD[((Int, Int), (Double, Double))] = MapPar
titionsRDD[3881] at join at :48
```
我们把结果输出,对比一下真实结果与预测结果:
```scala
scala> ratesAndPreds.foreach(println)
((3,1),(1.0,-0.22756397347958202))
((4,2),(5.0,4.388061223429636))
((4,1),(1.0,-0.1847678805249373))
```
比如,第一条结果记录((3,1),(1.0,-0.22756397347958202))中,(3,1)分别表示3号用户和1号商品,而1.0是实际的估计分值,-0.22756397347958202是经过推荐的预测分值。
然后计算均方差,这里的r1就是真实结果,r2就是预测结果:
```scala
scala> val MSE = ratesAndPreds.map { case ((user, product), (r1, r2)) =>
| val err = (r1 - r2)
| err * err
| }.mean()
MSE: Double = 1.0950191019929887
```
打印出均方差值 :
```scala
scala> println("Mean Squared Error = " + MSE)
Mean Squared Error = 1.0950191019929887
```
我们可以看到打分的均方差值为1.09左右。由于本例的数据量很少,预测的结果和实际相比有一定的差距。上面的例子只是对测试集进行了评分,我们还可以进一步的通过调用model.recommendProducts给特定的用户推荐商品以及model.recommendUsers来给特定商品推荐潜在用户。
[技术]
Wed Jan 04 2017 16:04:06 GMT+0800 (中国标准时间)
返回 [Spark MLlib入门教程](http://mocom.xmu.edu.cn/article/show/5858ab782b2730e00d70fa08/0/1)
## 一、方法简介
决策树(decision tree)是一种基本的分类与回归方法,这里主要介绍用于分类的决策树。决策树模式呈树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。学习时利用训练数据,根据损失函数最小化的原则建立决策树模型;预测时,对新的数据,利用决策树模型进行分类。
## 二、基本原理
决策树学习通常包括3个步骤:特征选择、决策树的生成和决策树的剪枝。
### (一)特征选择
特征选择在于选取对训练数据具有分类能力的特征,这样可以提高决策树学习的效率。通常特征选择的准则是信息增益(或信息增益比、基尼指数等),每次计算每个特征的信息增益,并比较它们的大小,选择信息增益最大(信息增益比最大、基尼指数最小)的特征。下面我们重点介绍一下特征选择的准则:信息增益。
首先定义信息论中广泛使用的一个度量标准——熵(entropy),它是表示随机变量不确定性的度量。熵越大,随机变量的不确定性就越大。而信息增益(informational entropy)表示得知某一特征后使得信息的不确定性减少的程度。简单的说,一个属性的信息增益就是由于使用这个属性分割样例而导致的期望熵降低。信息增益、信息增益比和基尼指数的具体定义如下:
**信息增益**:特征A对训练数据集D的信息增益$g(D,A)$,定义为集合D的经验熵$H(D)$与特征A给定条件下D的经验条件熵$H(D|A)$之差,即 $$ g(D,A)=H(D)-H(D|A) $$
**信息增益比**:特征A对训练数据集D的信息增益比$g_R(D,A)$定义为其信息增益$g(D,A)$与训练数据集D关于特征A的值的熵$H_A(D)$之比,即 $$ g_R(D,A)=\frac{g(D,A)}{H_A(D)}$$
其中,$HA(D) = - \sum_{i=1}^{n} \frac{\left|D_i\right|}{\left|D\right|}log_2\frac{\left|D_i\right|} {\left|D\right|}$,n是特征A取值的个数。
**基尼指数**:分类问题中,假设有K个类,样本点属于第K类的概率为$p_k$, 则概率分布的基尼指数定义为:
$$Gini(p) = \sum_1^{K} p_k(1 - p_k) $$ $$= 1-\sum_1^{K} p_k^2$$
### (二)决策树的生成
从根结点开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征,由该特征的不同取值建立子结点,再对子结点递归地调用以上方法,构建决策树;直到所有特征的信息增均很小或没有特征可以选择为止,最后得到一个决策树。
决策树需要有停止条件来终止其生长的过程。一般来说最低的条件是:当该节点下面的所有记录都属于同一类,或者当所有的记录属性都具有相同的值时。这两种条件是停止决策树的必要条件,也是最低的条件。在实际运用中一般希望决策树提前停止生长,限定叶节点包含的最低数据量,以防止由于过度生长造成的过拟合问题。
### (三)决策树的剪枝
决策树生成算法递归地产生决策树,直到不能继续下去为止。这样产生的树往往对训练数据的分类很准确,但对未知的测试数据的分类却没有那么准确,即出现过拟合现象。解决这个问题的办法是考虑决策树的复杂度,对已生成的决策树进行简化,这个过程称为剪枝。
决策树的剪枝往往通过极小化决策树整体的损失函数来实现。一般来说,损失函数可以进行如下的定义: $$ C_a(T)=C(T)+a\left|T\right| $$ 其中,T为任意子树,$C(T)$ 为对训练数据的预测误差(如基尼指数),$\left|T\right|$ 为子树的叶结点个数,$a\ge0$为参数,$C_a(T)$ 为参数是$a$时的子树T的整体损失,参数$a$权衡训练数据的拟合程度与模型的复杂度。对于固定的$a$,一定存在使损失函数$C_a(T)$ 最小的子树,将其表示为$T_a$ 。当$a$大的时候,最优子树$T_a$偏小;当$a$小的时候,最优子树$T_a$偏大。
### 示例代码
以iris数据集([https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data](https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data))为例进行分析。iris以鸢尾花的特征作为数据来源,数据集包含150个数据集,分为3类,每类50个数据,每个数据包含4个属性,是在数据挖掘、数据分类中非常常用的测试集、训练集。为了便于理解,我们这里主要用后两个属性(花瓣的长度和宽度)来进行分类。
##### 1. 导入需要的包:
```scala
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.sql.SQLContext
import org.apache.spark.ml.{Pipeline,PipelineModel}
import org.apache.spark.ml.classification.DecisionTreeClassificationModel
import org.apache.spark.ml.classification.DecisionTreeClassifier
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.feature.{IndexToString, StringIndexer, VectorIndexer,HashingTF, Tokenizer}
import org.apache.spark.mllib.linalg.{Vector,Vectors}
import org.apache.spark.sql.Row
import org.apache.spark.mllib.stat.{MultivariateStatisticalSummary, Statistics}
```
##### 2. 读取数据,简要分析:
首先根据SparkContext来创建一个SQLContext,其中sc是一个已经存在的SparkContext;然后导入sqlContext.implicits._来实现RDD到Dataframe的隐式转换。
```scala
scala> val sqlContext = new SQLContext(sc)
sqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@10d83860
scala> import sqlContext.implicits._
import sqlContext.implicits._
```
读取文本文件,第一个map把每行的数据用“,”隔开,每行被分成了5部分,前4部分是鸢尾花的4个特征,最后一部分是鸢尾花的分类。前面说到,这里主要用后两个属性(花瓣的长度和宽度)来进行分类,所以在下一个map中我们获取到这两个属性,存储在Vector中。
```scala
scala> val observations=sc.textFile("G:/spark/iris.data").map(_.split(",")).map(p => Vectors.dense(p(2).toDouble, p(3).toDouble))
observations: org.apache.spark.rdd.RDD[org.apache.spark.mllib.linalg.Vector] = MapPartitionsRDD[14] at map at :37
```
这里用case class定义一个schema:Iris,Iris就是需要的数据的结构;然后读取数据,创建一个Iris模式的RDD,然后转化成dataframe;最后调用show()方法来查看一下部分数据。
```scala
scala> case class Iris(features: Vector, label: String)
defined class Iris
scala> val data = sc.textFile("G:/spark/iris.data")
| .map(_.split(","))
| .map(p => Iris(Vectors.dense(p(2).toDouble, p(3).toDouble), p(4).toString()))
| .toDF()
data: org.apache.spark.sql.DataFrame = [features: vector, label: string]
scala> data.show()
+---------+-----------+
| features| label|
+---------+-----------+
|[1.4,0.2]|Iris-setosa|
|[1.4,0.2]|Iris-setosa|
|[1.3,0.2]|Iris-setosa|
|[1.5,0.2]|Iris-setosa|
|[1.4,0.2]|Iris-setosa|
|[1.7,0.4]|Iris-setosa|
|[1.4,0.3]|Iris-setosa|
|[1.5,0.2]|Iris-setosa|
|[1.4,0.2]|Iris-setosa|
|[1.5,0.1]|Iris-setosa|
|[1.5,0.2]|Iris-setosa|
|[1.6,0.2]|Iris-setosa|
|[1.4,0.1]|Iris-setosa|
|[1.1,0.1]|Iris-setosa|
|[1.2,0.2]|Iris-setosa|
|[1.5,0.4]|Iris-setosa|
|[1.3,0.4]|Iris-setosa|
|[1.4,0.3]|Iris-setosa|
|[1.7,0.3]|Iris-setosa|
|[1.5,0.3]|Iris-setosa|
+---------+-----------+
only showing top 20 rows
```
##### 3. 构建ML的pipeline
分别获取标签列和特征列,进行索引,并进行了重命名。
```scala
scala> val labelIndexer = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel").fit(data)
labelIndexer: org.apache.spark.ml.feature.StringIndexerModel = strIdx_6033e13b0b2b
scala> val featureIndexer = new VectorIndexer().setInputCol("features").setOutputCol("indexedFeatures").fit(data)
featureIndexer: org.apache.spark.ml.feature.VectorIndexerModel = vecIdx_b5a8adea6903
```
接下来,把数据集随机分成训练集和测试集,其中训练集占70%。
```scala
scala> val Array(trainingData, testData) = data.randomSplit(Array(0.7, 0.3))
trainingData: org.apache.spark.sql.DataFrame = [features: vector, label: string]
testData: org.apache.spark.sql.DataFrame = [features: vector, label: string]
```
然后,设置决策树的参数。这里统一用setter的方法来设置,也可以用ParamMap来设置(具体的可以查看spark mllib的官网)。这里设置了用gini指数来进行特征选择,设置树的最大深度为5,具体的可以设置的参数可以通过explainParams()来获取,还能看已经设置的参数的结果。
```scala
scala> val dt = new DecisionTreeClassifier()
| .setLabelCol("indexedLabel")
| .setFeaturesCol("indexedFeatures")
| .setImpurity("gini")
| .setMaxDepth(5)
dt: org.apache.spark.ml.classification.DecisionTreeClassifier = dtc_16842f2bb6a7
scala> println("DecisionTreeClassifier parameters:\n" + dt.explainParams() + "\n")
DecisionTreeClassifier parameters:
cacheNodeIds: If false, the algorithm will pass trees to executors to match instances with nodes. If true, the algorithm will cache node IDs for each instance. Caching can speed up training of deeper trees. (default: false)
checkpointInterval: set checkpoint interval (>= 1) or disable checkpoint (-1). E.g. 10 means that the cache will get checkpointed every 10 iterations (default:10)
featuresCol: features column name (default: features, current: indexedFeatures)
impurity: Criterion used for information gain calculation (case-insensitive). Supported options: entropy, gini (default: gini, current: gini)
labelCol: label column name (default: label, current: indexedLabel)
maxBins: Max number of bins for discretizing continuous features. Must be >=2 and >= number of categories for any categorical feature. (default: 32)
maxDepth: Maximum depth of the tree. (>= 0) E.g., depth 0 means 1 leaf node; depth 1 means 1 internal node + 2 leaf nodes. (default: 5, current: 5)
maxMemoryInMB: Maximum memory in MB allocated to histogram aggregation. (default: 256)
minInfoGain: Minimum information gain for a split to be considered at a tree node. (default: 0.0)
minInstancesPerNode: Minimum number of instances each child must have after split. If a split causes the left or right child to have fewer than minInstancesPerNode, the split will be discarded as invalid. Should be >= 1. (default: 1)
predictionCol: prediction column name (default: prediction)
probabilityCol: Column name for predicted class conditional probabilities. Note: Not all models output well-calibrated probability estimates! These probabilities should be treated as confidences, not precise probabilities (default: probability)
rawPredictionCol: raw prediction (a.k.a. confidence) column name (default: rawPrediction)
seed: random seed (default: 159147643)
thresholds: Thresholds in multi-class classification to adjust the probability of predicting each class. Array must have length equal to the number of classes, with values >= 0. The class with largest value p/t is predicted, where p is the original probability of that class and t is the class' threshold. (undefined)
```
这里设置一个labelConverter,目的是把预测的类别重新转化成字符型的。
```scala
scala> val labelConverter = new IndexToString().
| setInputCol("prediction").
| setOutputCol("predictedLabel").
| setLabels(labelIndexer.labels)
labelConverter: org.apache.spark.ml.feature.IndexToString = idxToStr_5c051ba9ebd3
```
构建pipeline,设置stage,然后调用fit()来训练模型。
```scala
scala> val pipeline = new Pipeline().
| setStages(Array(labelIndexer, featureIndexer, dt, labelConverter))
pipeline: org.apache.spark.ml.Pipeline = pipeline_eb9649610b0f
// Fit the pipeline to training documents.
scala> val model = pipeline.fit(trainingData)
model: org.apache.spark.ml.PipelineModel = pipeline_eb9649610b0f
```
pipeline本质上是一个Estimator,当pipeline调用fit()的时候就产生了一个PipelineModel,本质上是一个Transformer。然后这个PipelineModel就可以调用transform()来进行预测,生成一个新的DataFrame,即利用训练得到的模型对测试集进行验证。
```scala
scala> val predictions = model.transform(testData)
predictions: org.apache.spark.sql.DataFrame = [features: vector, label: string,
indexedLabel: double, indexedFeatures: vector, rawPrediction: vector, probabilit
y: vector, prediction: double, predictedLabel: string]
```
最后可以输出预测的结果,其中select选择要输出的列,collect获取所有行的数据,用foreach把每行打印出来。
```scala
scala> predictions.
| select("predictedLabel", "label", "features").
| collect().
| foreach { case Row(predictedLabel: String, label: String, features:
Vector) =>
| println(s"($label, $features) --> predictedLabel=$predictedLabel")
| }
(Iris-setosa, [1.2,0.2]) --> predictedLabel=Iris-setosa
(Iris-setosa, [1.3,0.3]) --> predictedLabel=Iris-setosa
(Iris-setosa, [1.3,0.4]) --> predictedLabel=Iris-setosa
(Iris-setosa, [1.4,0.2]) --> predictedLabel=Iris-setosa
(Iris-setosa, [1.4,0.2]) --> predictedLabel=Iris-setosa
(Iris-setosa, [1.4,0.2]) --> predictedLabel=Iris-setosa
(Iris-setosa, [1.5,0.1]) --> predictedLabel=Iris-setosa
(Iris-setosa, [1.5,0.2]) --> predictedLabel=Iris-setosa
(Iris-setosa, [1.6,0.2]) --> predictedLabel=Iris-setosa
(Iris-setosa, [1.6,0.2]) --> predictedLabel=Iris-setosa
(Iris-setosa, [1.6,0.2]) --> predictedLabel=Iris-setosa
(Iris-setosa, [1.7,0.2]) --> predictedLabel=Iris-setosa
(Iris-setosa, [1.7,0.4]) --> predictedLabel=Iris-setosa
(Iris-setosa, [1.9,0.2]) --> predictedLabel=Iris-setosa
(Iris-versicolor, [4.0,1.0]) --> predictedLabel=Iris-versicolor
... ...
```
##### 4. 模型评估
创建一个MulticlassClassificationEvaluator实例,用setter方法把预测分类的列名和真实分类的列名进行设置;然后计算预测准确率和错误率。
```scala
scala> val evaluator = new MulticlassClassificationEvaluator().
| setLabelCol("indexedLabel").
| setPredictionCol("prediction")
evaluator: org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator = mc Eval_4651752eb9e9
scala> val accuracy = evaluator.evaluate(predictions)
accuracy: Double = 0.96
scala> println("Test Error = " + (1.0 - accuracy))
Test Error = 0.040000000000000036
```
从上面可以看到预测的准确性达到96%,接下来可以通过model来获取我们训练得到的决策树模型。前面已经说过model是一个PipelineModel,因此可以通过调用它的stages来获取模型,具体如下:
```scala
scala> val treeModel = model.stages(2).asInstanceOf[DecisionTreeClassificationModel]
treeModel: org.apache.spark.ml.classification.DecisionTreeClassificationModel =
DecisionTreeClassificationModel (uid=dtc_16842f2bb6a7) of depth 4 with 13 nodes
scala> println("Learned classification tree model:\n" + treeModel.toDebugString)
Learned classification tree model:
DecisionTreeClassificationModel (uid=dtc_16842f2bb6a7) of depth 4 with 13 nodes
If (feature 0 <= 1.9)
Predict: 2.0
Else (feature 0 > 1.9)
If (feature 1 <= 1.7)
If (feature 0 <= 4.9)
If (feature 1 <= 1.6)
Predict: 0.0
Else (feature 1 > 1.6)
Predict: 1.0
Else (feature 0 > 4.9)
If (feature 1 <= 1.6)
Predict: 1.0
Else (feature 1 > 1.6)
Predict: 0.0
Else (feature 1 > 1.7)
If (feature 0 <= 4.8)
Predict: 0.0
Else (feature 0 > 4.8)
Predict: 1.0
```
[技术]
Fri Dec 30 2016 23:18:59 GMT+0800 (中国标准时间)
返回 [Spark MLlib入门教程](http://mocom.xmu.edu.cn/article/show/5858ab782b2730e00d70fa08/0/1)
### 方法简介
逻辑斯蒂回归(logistic regression)是统计学习中的经典分类方法,属于对数线性模型。logistic回归的因变量可以是二分类的,也可以是多分类的。
### 基本原理
##### logistic分布
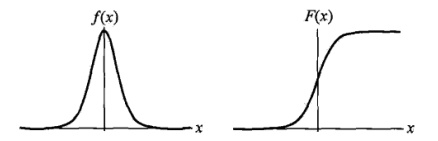
设X是连续随机变量,X服从logistic分布是指X具有下列分布函数和密度函数:
$$F(x)=P(x \le x)=\frac 1 {1+e^{-(x-\mu)/\gamma}}$$
$$f(x)=F^{'}(x)=\frac {e^{-(x-\mu)/\gamma}} {\gamma(1+e^{-(x-\mu)/\gamma})^2}$$
其中,$\mu$为位置参数,$\gamma$为形状参数。
$f(x)$与$F(x)$图像如下,其中分布函数是以$(\mu, \frac 1 2)$为中心对阵,$\gamma$越小曲线变化越快。
##### 
##### 二项logistic回归模型:
二项logistic回归模型如下:
$$P(Y=1|x)=\frac {exp(w \cdot x + b)} {1 + exp(w \cdot x + b)}$$
$$P(Y=0|x)=\frac {1} {1 + exp(w \cdot x + b)}$$
其中,$x \in R^n$是输入,$Y \in {0,1}$是输出,w称为权值向量,b称为偏置,$w \cdot x$为w和x的内积。
##### 参数估计
假设:
$$P(Y=1|x)=\pi (x), \quad P(Y=0|x)=1-\pi (x)$$
则采用“极大似然法”来估计w和b。似然函数为:
$$\prod_{i=1}^N [\pi (x_i)]^{y_i} [1 - \pi(x_i)]^{1-y_i}$$
为方便求解,对其“对数似然”进行估计:
$$L(w) = \sum_{i=1}^N [y_i \log{\pi(x_i)} + (1-y_i) \log{(1 - \pi(x_i)})]$$
从而对$L(w)$求极大值,得到$w$的估计值。求极值的方法可以是梯度下降法,梯度上升法等。
### 示例代码
我们以iris数据集([https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data](https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data))为例进行分析。iris以鸢尾花的特征作为数据来源,数据集包含150个数据集,分为3类,每类50个数据,每个数据包含4个属性,是在数据挖掘、数据分类中非常常用的测试集、训练集。为了便于理解,这里主要用后两个属性(花瓣的长度和宽度)来进行分类。由于目前 `spark.ml` 中只支持二分类,此处取其中的后两类数据进行分析。
##### 1. 导入需要的包:
```scala
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.sql.SQLContext
import org.apache.spark.ml.{Pipeline,PipelineModel}
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.feature.{IndexToString, StringIndexer, VectorIndexer,HashingTF, Tokenizer}
import org.apache.spark.mllib.linalg.{Vector,Vectors}
import org.apache.spark.sql.Row
import org.apache.spark.mllib.stat.{MultivariateStatisticalSummary, Statistics}
import org.apache.spark.ml.classification.LogisticRegressionModel
```
##### 2. 读取数据,简要分析:
首先根据SparkContext来创建一个SQLContext,其中sc是一个已经存在的SparkContext;然后导入sqlContext.implicits._来实现RDD到Dataframe的隐式转换。
```scala
scala> val sqlContext = new SQLContext(sc)
sqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@10d83860
scala> import sqlContext.implicits._
import sqlContext.implicits._
```
读取文本文件,第一个map把每行的数据用“,”隔开。比如数据集中,每行被分成了5部分,前4部分是鸢尾花的4个特征,最后一部分是鸢尾花的分类;前面说到,我们这里主要用后两个属性(花瓣的长度和宽度)来进行分类,所以在下一个map中我们获取到这两个属性,存储在Vector中。
```scala
scala> val observations=sc.textFile("G:/spark/iris.data").map(_.split(",")).map(p => Vectors.dense(p(2).toDouble, p(3).toDouble))
observations: org.apache.spark.rdd.RDD[org.apache.spark.mllib.linalg.Vector] = MapPartitionsRDD[14] at map at :37
```
接下来,调用mllib.stat中的统计方法得到数据的基本的统计信息,例如均值、方差等。[`colStats()`](http://spark.apache.org/docs/1.6.2/api/scala/index.html#org.apache.spark.mllib.stat.Statistics$) 方法返回一个 [`MultivariateStatisticalSummary`](http://spark.apache.org/docs/1.6.2/api/scala/index.html#org.apache.spark.mllib.stat.MultivariateStatisticalSummary)的实例,其中包含每列的最大值、最小值、均值等等。这里简单的列出了一些基本的统计结果。
```scala
scala> val summary: MultivariateStatisticalSummary = Statistics.colStats(observations)
summary: org.apache.spark.mllib.stat.MultivariateStatisticalSummary = org.apache.spark.mllib.stat.MultivariateOnlineSummarizer@1a5462ad
scala> println(summary.mean)
[3.7586666666666666,1.1986666666666668]
scala> println(summary.variance)
[3.113179418344516,0.5824143176733783]
scala> println(summary.numNonzeros)
[150.0,150.0]
```
用case class定义一个schema:Iris,Iris就是需要的数据的结构;然后读取数据,创建一个Iris模式的RDD,然后转化成dataframe;最后调用show()方法来查看一下部分数据。
```scala
scala> case class Iris(features: Vector, label: String)
defined class Iris
scala> val data = sc.textFile("G:/spark/iris.data")
| .map(_.split(","))
| .map(p => Iris(Vectors.dense(p(2).toDouble, p(3).toDouble), p(4).toString()))
| .toDF()
data: org.apache.spark.sql.DataFrame = [features: vector, label: string]
scala> data.show()
+---------+-----------+
| features| label|
+---------+-----------+
|[1.4,0.2]|Iris-setosa|
|[1.4,0.2]|Iris-setosa|
|[1.3,0.2]|Iris-setosa|
|[1.5,0.2]|Iris-setosa|
|[1.4,0.2]|Iris-setosa|
|[1.7,0.4]|Iris-setosa|
|[1.4,0.3]|Iris-setosa|
|[1.5,0.2]|Iris-setosa|
|[1.4,0.2]|Iris-setosa|
|[1.5,0.1]|Iris-setosa|
|[1.5,0.2]|Iris-setosa|
|[1.6,0.2]|Iris-setosa|
|[1.4,0.1]|Iris-setosa|
|[1.1,0.1]|Iris-setosa|
|[1.2,0.2]|Iris-setosa|
|[1.5,0.4]|Iris-setosa|
|[1.3,0.4]|Iris-setosa|
|[1.4,0.3]|Iris-setosa|
|[1.7,0.3]|Iris-setosa|
|[1.5,0.3]|Iris-setosa|
+---------+-----------+
only showing top 20 rows
```
有的时候不需要全部的数据,比如ml库中的logistic回归目前只支持2分类,所以要从中选出两类的数据。这里首先把刚刚得到的数据注册成一个表iris,注册成这个表之后,就可以通过sql语句进行数据查询,比如这里选出了所有不属于“Iris-setosa”类别的数据。选出需要的数据后,把结果打印出来看一下,这时就已经没有“Iris-setosa”类别的数据。
```scala
scala> data.registerTempTable("iris")
scala> val df = sqlContext.sql("select * from iris where label != 'Iris-setosa'")
df: org.apache.spark.sql.DataFrame = [features: vector, label: string]
scala> df.map(t => t(1)+":"+t(0)).collect().foreach(println)
Iris-versicolor:[4.7,1.4]
Iris-versicolor:[4.5,1.5]
Iris-versicolor:[4.9,1.5]
Iris-versicolor:[4.0,1.3]
Iris-versicolor:[4.6,1.5]
Iris-versicolor:[4.5,1.3]
... ...
```
##### 3. 构建ML的pipeline
分别获取标签列和特征列,进行索引,并进行了重命名。
```scala
scala> val labelIndexer = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel").fit(df)
labelIndexer: org.apache.spark.ml.feature.StringIndexerModel = strIdx_a14ddbf05040
scala> val featureIndexer = new VectorIndexer().setInputCol("features").setOutputCol("indexedFeatures").fit(df)
featureIndexer: org.apache.spark.ml.feature.VectorIndexerModel = vecIdx_755d3f41691a
```
接下来,把数据集随机分成训练集和测试集,其中训练集占70%。
```scala
scala> val Array(trainingData, testData) = df.randomSplit(Array(0.7, 0.3))
trainingData: org.apache.spark.sql.DataFrame = [features: vector, label: string]
testData: org.apache.spark.sql.DataFrame = [features: vector, label: string]
```
然后,设置logistic的参数,这里我们统一用setter的方法来设置,也可以用ParamMap来设置(具体的可以查看spark mllib的官网)。这里设置了循环次数为10次,正则化项为0.3等,具体的可以设置的参数可以通过explainParams()来获取,还能看到程序已经设置的参数的结果。
```scala
scala> val lr = new LogisticRegression().
| setLabelCol("indexedLabel").
| setFeaturesCol("indexedFeatures").
| setMaxIter(10).
| setRegParam(0.3).
| setElasticNetParam(0.8)
lr: org.apache.spark.ml.classification.LogisticRegression = logreg_a58ee56c357f
scala> println("LogisticRegression parameters:\n" + lr.explainParams() + "\n")
LogisticRegression parameters:
elasticNetParam: the ElasticNet mixing parameter, in range [0, 1]. For alpha = 0, the penalty is an L2 penalty. For alpha = 1, it is an L1 penalty (default: 0.0, current: 0.8)
featuresCol: features column name (default: features, current: indexedFeatures)
fitIntercept: whether to fit an intercept term (default: true)
labelCol: label column name (default: label, current: indexedLabel)
maxIter: maximum number of iterations (>= 0) (default: 100, current: 10)
predictionCol: prediction column name (default: prediction)
probabilityCol: Column name for predicted class conditional probabilities. Note: Not all models output well-calibrated probability estimates! These probabilities should be treated as confidences, not precise probabilities (default: probability)
rawPredictionCol: raw prediction (a.k.a. confidence) column name (default: rawPrediction)
regParam: regularization parameter (>= 0) (default: 0.0, current: 0.3)
standardization: whether to standardize the training features before fitting the model (default: true)
threshold: threshold in binary classification prediction, in range [0, 1] (default: 0.5)
thresholds: Thresholds in multi-class classification to adjust the probability of predicting each class. Array must have length equal to the number of classes, with values >= 0. The class with largest value p/t is predicted, where p is the original probability of that class and t is the class' threshold. (undefined)
tol: the convergence tolerance for iterative algorithms (default: 1.0E-6)
weightCol: weight column name. If this is not set or empty, we treat all instance weights as 1.0. (default: )
```
这里设置一个labelConverter,目的是把预测的类别重新转化成字符型的。
```scala
scala> val labelConverter = new IndexToString().
| setInputCol("prediction").
| setOutputCol("predictedLabel").
| setLabels(labelIndexer.labels)
labelConverter: org.apache.spark.ml.feature.IndexToString = idxToStr_89b2b1508b35
```
构建pipeline,设置stage,然后调用fit()来训练模型。
```scala
scala> val pipeline = new Pipeline().
| setStages(Array(labelIndexer, featureIndexer, lr, labelConverter))
pipeline: org.apache.spark.ml.Pipeline = pipeline_33fa7f88685a
scala> val model = pipeline.fit(trainingData)
model: org.apache.spark.ml.PipelineModel = pipeline_33fa7f88685a
```
pipeline本质上是一个评估器(Estimator),当pipeline调用fit()的时候就产生了一个PipelineModel,本质上是一个转换器(Transformer)。然后这个PipelineModel就可以调用transform()来进行预测,生成一个新的DataFrame,即利用训练得到的模型对测试集进行验证。
```scala
scala> val predictions = model.transform(testData)
predictions: org.apache.spark.sql.DataFrame = [features: vector, label: string,
indexedLabel: double, indexedFeatures: vector, rawPrediction: vector, probabilit
y: vector, prediction: double, predictedLabel: string]
```
最后输出预测的结果,其中select选择要输出的列,collect获取所有行的数据,用foreach把每行打印出来。
```scala
scala> predictions.
| select("predictedLabel", "label", "features", "probability").
| collect().
| foreach { case Row(predictedLabel: String, label: String, features: Vector, prob: Vector) =>
| println(s"($label, $features) --> prob=$prob, predictedLabel=$predictedLabel")
| }
(Iris-versicolor, [3.5,1.0]) --> prob=[0.6949117083297265,0.30508829167027346], predictedLabel=Iris-versicolor
(Iris-versicolor, [4.1,1.0]) --> prob=[0.694606868968713,0.30539313103128685], predictedLabel=Iris-versicolor
(Iris-versicolor, [4.3,1.3]) --> prob=[0.6060637422536634,0.3939362577463365], predictedLabel=Iris-versicolor
(Iris-versicolor, [4.4,1.4]) --> prob=[0.5745401752760255,0.4254598247239745], predictedLabel=Iris-versicolor
(Iris-versicolor, [4.5,1.3]) --> prob=[0.6059493387519529,0.39405066124804705],
predictedLabel=Iris-versicolor
(Iris-versicolor, [4.5,1.5]) --> prob=[0.5423986730485701,0.45760132695142974],
... ...
```
##### 4. 模型评估
创建一个MulticlassClassificationEvaluator实例,用setter方法把预测分类的列名和真实分类的列名进行设置;然后计算预测准确率和错误率。
```scala
scala> val evaluator = new MulticlassClassificationEvaluator().
| setLabelCol("indexedLabel").
| setPredictionCol("prediction")
evaluator: org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator = mc
Eval_198b7e595a62
scala> val accuracy = evaluator.evaluate(predictions)
accuracy: Double = 0.9411764705882353
scala> println("Test Error = " + (1.0 - accuracy))
Test Error = 0.05882352941176472
```
从上面可以看到预测的准确性达到94.1%,接下来可以通过model来获取训练得到的逻辑斯蒂模型。前面已经说过model是一个PipelineModel,因此可以通过调用它的stages来获取模型,具体如下:
```scala
scala> val lrModel = model.stages(2).asInstanceOf[LogisticRegressionModel]
lrModel: org.apache.spark.ml.classification.LogisticRegressionModel = logreg_a58ee56c357f
scala> println("Coefficients: " + lrModel.coefficients+"Intercept: "+lrModel.intercept+
| "numClasses: "+lrModel.numClasses+"numFeatures: "+lrModel.numFeatures)
Coefficients: [0.0023957582955816056,0.13015697498232498]Intercept: -0.8315687375527291numClasses: 2numFeatures: 2
```
[技术]
Fri Dec 30 2016 23:14:52 GMT+0800 (中国标准时间)
返回 [Spark MLlib入门教程](http://mocom.xmu.edu.cn/article/show/5858ab782b2730e00d70fa08/0/1)
## 二、主成分分析(PCA)
### 1、概念介绍
**主成分分析(PCA)** 是一种对数据进行旋转变换的统计学方法,其本质是在线性空间中进行一个基变换,使得变换后的数据投影在一组新的“坐标轴”上的方差最大化,随后,裁剪掉变换后方差很小的“坐标轴”,剩下的新“坐标轴”即被称为 **主成分(Principal Component)** ,它们可以在一个较低维度的子空间中尽可能地表示原有数据的性质。主成分分析被广泛应用在各种统计学、机器学习问题中,是最常见的降维方法之一。PCA有许多具体的实现方法,可以通过计算协方差矩阵,甚至是通过上文提到的SVD分解来进行PCA变换。
### 2、PCA变换
MLlib提供了两种进行PCA变换的方法,第一种与上文提到的SVD分解类似,位于`org.apache.spark.mllib.linalg`包下的`RowMatrix`中,这里,我们同样读入上文中提到的`a.mat`文件,对其进行PCA变换:
```scala
scala> import org.apache.spark.mllib.linalg.Vectors
scala> import org.apache.spark.mllib.linalg.distributed.RowMatrix
scala> val data = sc.textFile("a.mat").map(_.split(" ").map(_.toDouble)).map(line => Vectors.dense(line))
data: org.apache.spark.rdd.RDD[org.apache.spark.mllib.linalg.Vector] = MapPartitionsRDD[3] at map at :31
//通过RDD[Vectors]创建行矩阵
scala> val rm = new RowMatrix(data)
rm: org.apache.spark.mllib.linalg.distributed.RowMatrix = org.apache.spark.mllib.linalg.distributed.RowMatrix@4397952a
//保留前3个主成分
scala> val pc = rm.computePrincipalComponents(3)
pc: org.apache.spark.mllib.linalg.Matrix =
-0.41267731212833847 -0.3096216957951525 0.1822187433607524
0.22357946922702987 -0.08150768817940773 0.5905947537762997
-0.08813803143909382 -0.5339474873283436 -0.2258410886711858
0.07580492185074224 -0.56869017430423 -0.28981327663106565
0.4399389896865264 -0.23105821586820194 0.3185548657550075
-0.08276152212493619 0.3798283369681188 -0.4216195003799105
0.3952116027336311 -0.19598446496556066 -0.17237034054712738
0.43580231831608096 -0.023441639969444372 -0.4151661847170216
0.468703853681766 0.2288352748369381 0.04103087747663084
```
可以看到,主成分矩阵是一个尺寸为(9,3)的矩阵,其中每一列代表一个主成分(新坐标轴),每一行代表原有的一个特征,而`a.mat`矩阵可以看成是一个有4个样本,9个特征的数据集,那么,主成分矩阵相当于把原有的9维特征空间投影到一个3维的空间中,从而达到降维的效果。
可以通过矩阵乘法来完成对原矩阵的PCA变换,可以看到原有的(4,9)矩阵被变换成新的(4,3)矩阵。
```scala
scala> val projected = rm.multiply(pc)
projected: org.apache.spark.mllib.linalg.distributed.RowMatrix = org.apache.spark.mllib.linalg.distributed.RowMatrix@2a805829
scala> projected.rows.foreach(println)
[12.247647483894383,-2.725468189870252,-5.568954759405281]
[2.8762985358626505,-2.2654415718974685,1.428630138613534]
[12.284448024169402,-12.510510992280857,-0.16048149283293078]
[-1.2537294080109986,-10.15675264890709,-4.8697886049036025]
```
需要注意的是,MLlib提供的PCA变换方法最多只能处理65535维的数据。
### 3、“模型式”的PCA变换实现
除了矩阵类内置的PCA变换外,MLlib还提供了一种“模型式”的PCA变换实现,它位于`org.apache.spark.mllib.feature`包下的`PCA`类,它可以接受`RDD[Vectors]`作为参数,进行PCA变换。
该方法特别适用于原始数据是`LabeledPoint`类型的情况,只需取出`LabeledPoint`的`feature`成员(它是`RDD[Vector]`类型),对其做PCA操作后再放回,即可在不影响原有标签情况下进行PCA变换。
首先引入需要使用到的类:
```scala
import org.apache.spark.mllib.feature.PCA
import org.apache.spark.mllib.regression.LabeledPoint
```
依然使用前文的`a.mat`矩阵,为了创造出`LabeledPoint`,我们为第一个样本标注标签为`0.0`,其他为`1.0`。
```scala
scala> val data = sc.textFile("a.mat").map(_.split(" ").map(_.toDouble)).map(line => {
| LabeledPoint( if(line(0) > 1.0) 1.toDouble else 0.toDouble, Vectors.dense(line) )
| })
data: org.apache.spark.rdd.RDD[org.apache.spark.mllib.regression.LabeledPoint] = MapPartitionsRDD[16] at map at :34
scala> data.foreach(println)
(0.0,[1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0])
(1.0,[6.0,4.0,2.0,1.0,3.0,4.0,2.0,1.0,5.0])
(1.0,[5.0,6.0,7.0,8.0,9.0,0.0,8.0,6.0,7.0])
(1.0,[9.0,0.0,8.0,7.0,1.0,4.0,3.0,2.0,1.0])
```
随后,创建一个`PCA`类的对象,在构造器中给定主成分个数为3,并调用其`fit`方法来生成一个`PCAModel`类的对象`pca`,该对象保存了对应的主成分矩阵:
```scala
scala> val pca = new PCA(3).fit(data.map(_.features))
pca: org.apache.spark.mllib.feature.PCAModel = org.apache.spark.mllib.feature.PCAModel@68602c26
```
对于`LabeledPoint`型的数据来说,可使用`map`算子对每一条数据进行处理,将`features`成员替换成PCA变换后的特征即可:
```scala
scala> val projected = data.map(p => p.copy(features = pca.transform(p.features)))
projected: org.apache.spark.rdd.RDD[org.apache.spark.mllib.regression.LabeledPoint] = MapPartitionsRDD[20] at map at :39
scala> projected.foreach(println)
(0.0,[12.247647483894383,-2.725468189870252,-5.568954759405281])
(1.0,[2.8762985358626505,-2.2654415718974685,1.428630138613534])
(1.0,[12.284448024169402,-12.510510992280857,-0.16048149283293078])
(1.0,[-1.2537294080109986,-10.15675264890709,-4.8697886049036025])
```
[技术]
Tue Dec 27 2016 22:26:55 GMT+0800 (中国标准时间)