返回 [Spark MLlib入门教程](http://mocom.xmu.edu.cn/article/show/5858ab782b2730e00d70fa08/0/1)
---
## 方法简介
支持向量机是一种二分类模型。它的基本模型是定义在特征空间上的间隔最大的线性分类器。支持向量机学习方法包含3种模型:线性可分支持向量机、线性支持向量机及非线性支持向量机。当训练数据线性可分时,通过硬间隔最大化,学习一个线性的分类器,即线性可分支持向量机;当训练数据近似线性可分时,通过软间隔最大化,也学习一个线性的分类器,即线性支持向量机;当训练数据线性不可分时,通过使用核技巧及软间隔最大化,学习非线性支持向量机。线性支持向量机支持L1和L2的正则化变型。关于正则化,可以参见http://spark.apache.org/docs/1.6.2/mllib-linear-methods.html#regularizers
## 基本原理
支持向量机,因其英文名为support vector machine,故一般简称SVM。SVM从线性可分情况下的最优分类面发展而来。最优分类面就是要求分类线不但能将两类正确分开(训练错误率为0),且使分类间隔最大。SVM考虑寻找一个满足分类要求的超平面,并且使训练集中的点距离分类面尽可能的远,也就是寻找一个分类面使它两侧的空白区域(margin)最大。这两类样本中离分类面最近,且平行于最优分类面的超平面上的点,就叫做支持向量(下图中红色的点)。
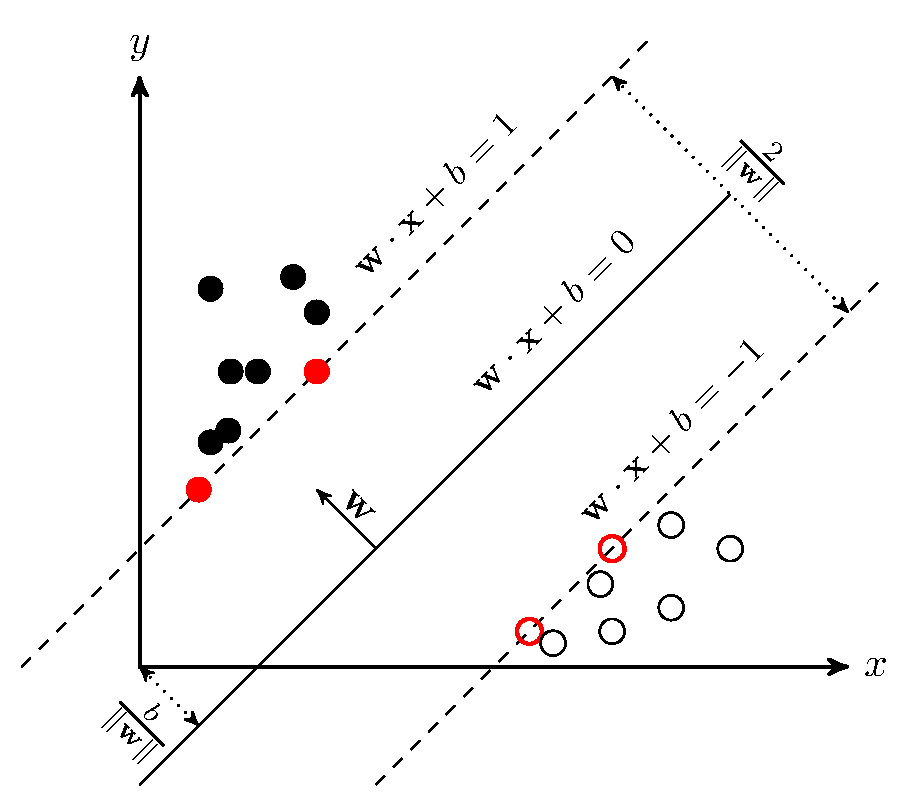
假设超平面可描述为:
$$
wx+b=0, w\in R^n, b\in R
$$
其分类间隔等于$\frac{2}{||w||}$。其学习策略是使数据间的间隔最大化,最终可转化为一个凸二次规划问题的求解。
分类器的损失函数(hinge loss铰链损失)如下所示:
$$
L(w;x,y):=max(0,1-yw^Tx)
$$
默认情况下,线性SVM是用L2 正则化来训练的,但也支持L1正则化。在这种情况下,这个问题就变成了一个线性规划。
线性SVM算法输出一个SVM模型。给定一个新的数据点,比如说$x$,这个模型就会根据$w^Tx$ 的值来进行预测。默认情况下,如果$w^Tx \ge 0$ ,则输出预测结果为正(因为我们想要损失函数最小,如果预测为负,则会导致损失函数大于1),反之则预测为负。
## 示例代码
下面的例子具体介绍了如何读入一个数据集,然后用SVM对训练数据进行训练,然后用训练得到的模型对测试集进行预测,并计算错误率。以iris数据集([https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data](https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data))为例进行分析。iris以鸢尾花的特征作为数据来源,数据集包含150个数据集,分为3类,每类50个数据,每个数据包含4个属性,是在数据挖掘、数据分类中非常常用的测试集、训练集。
### 1. 导入需要的包:
首先,我们导入需要的包:
```scala
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.linalg.{Vectors,Vector}
import org.apache.spark.mllib.classification.{SVMModel, SVMWithSGD}
import org.apache.spark.mllib.evaluation.BinaryClassificationMetrics
```
### 2. 读取数据:
首先,读取文本文件;然后,通过map将每行的数据用“,”隔开,在我们的数据集中,每行被分成了5部分,前4部分是鸢尾花的4个特征,最后一部分是鸢尾花的分类。把这里我们用LabeledPoint来存储标签列和特征列。LabeledPoint在监督学习中常用来存储标签和特征,其中要求标签的类型是double,特征的类型是Vector。所以,我们把莺尾花的分类进行了一下改变,"Iris-setosa"对应分类0,"Iris-versicolor"对应分类1,其余对应分类2;然后获取莺尾花的4个特征,存储在Vector中。
```scala
scala> val data = sc.textFile("G:/spark/iris.data")
data: org.apache.spark.rdd.RDD[String] = G:/spark/iris.data MapPartitionsRDD[1]
at textFile at :28
scala> val parsedData = data.map { line =>
| val parts = line.split(',')
| LabeledPoint(if(parts(4)=="Iris-setosa") 0.toDouble else if (parts(4)
=="Iris-versicolor") 1.toDouble else
| 2.toDouble, Vectors.dense(parts(0).toDouble,parts(1).toDouble,parts
(2).toDouble,parts(3).toDouble))
| }
parsedData: org.apache.spark.rdd.RDD[org.apache.spark.mllib.regression.LabeledPo
int] = MapPartitionsRDD[2] at map at :30
```
### 3. 构建模型
因为SVM只支持2分类,所以我们要进行一下数据抽取,这里我们通过filter过滤掉第2类的数据,只选取第0类和第1类的数据。然后,我们把数据集划分成两部分,其中训练集占60%,测试集占40%:
```scala
scala> val splits = parsedData.filter { point => point.label != 2 }.randomSplit(
Array(0.6, 0.4), seed = 11L)
splits: Array[org.apache.spark.rdd.RDD[org.apache.spark.mllib.regression.Labeled
Point]] = Array(MapPartitionsRDD[4] at randomSplit at :32, MapPartition
sRDD[5] at randomSplit at :32)
scala> val training = splits(0).cache()
training: org.apache.spark.rdd.RDD[org.apache.spark.mllib.regression.LabeledPoin
t] = MapPartitionsRDD[4] at randomSplit at :32
scala> val test = splits(1)
test: org.apache.spark.rdd.RDD[org.apache.spark.mllib.regression.LabeledPoint] =
MapPartitionsRDD[5] at randomSplit at :32
```
接下来,通过训练集构建模型SVMWithSGD。这里的SGD即著名的随机梯度下降算法(Stochastic Gradient Descent)。设置迭代次数为1000,除此之外还有stepSize(迭代步伐大小),regParam(regularization正则化控制参数),miniBatchFraction(每次迭代参与计算的样本比例),initialWeights(weight向量初始值)等参数可以进行设置。
```scala
scala> val numIterations = 1000
numIterations: Int = 1000
scala> val model = SVMWithSGD.train(training, numIterations)
model: org.apache.spark.mllib.classification.SVMModel = org.apache.spark.mllib.c
lassification.SVMModel: intercept = 0.0, numFeatures = 4, numClasses = 2, thresh
old = 0.0
```
### 4. 模型评估
接下来,我们清除默认阈值,这样会输出原始的预测评分,即带有确信度的结果。
```scala
scala> model.clearThreshold()
res0: model.type = org.apache.spark.mllib.classification.SVMModel: intercept = 0
.0, numFeatures = 4, numClasses = 2, threshold = None
scala> val scoreAndLabels = test.map { point =>
| val score = model.predict(point.features)
| (score, point.label)
| }
scoreAndLabels: org.apache.spark.rdd.RDD[(Double, Double)] = MapPartitionsRDD[11
] at map at :42
scala> scoreAndLabels.foreach(println)
(-3.0127314882950778,0.0)
(-2.4596261094505403,0.0)
(-2.64505513159329,0.0)
(-3.503342620026854,0.0)
(-2.717199557755541,0.0)
(-2.6779191149350754,0.0)
... ...
```
那如果设置了阈值,则会把大于阈值的结果当成正预测,小于阈值的结果当成负预测。
```scala
scala> model.setThreshold(0.0)
res0: model.type = org.apache.spark.mllib.classification.SVMModel: intercept = 0
.0, numFeatures = 4, numClasses = 2, threshold = 0
scala> scoreAndLabels.foreach(println)
(0.0,0.0)
(0.0,0.0)
(0.0,0.0)
(0.0,0.0)
(0.0,0.0)
(0.0,0.0)
... ...
```
最后,我们构建评估矩阵,把模型预测的准确性打印出来:
```scala
scala> val metrics = new BinaryClassificationMetrics(scoreAndLabels)
metrics: org.apache.spark.mllib.evaluation.BinaryClassificationMetrics = org.apa
che.spark.mllib.evaluation.BinaryClassificationMetrics@12468ced
scala> val auROC = metrics.areaUnderROC()
auROC: Double = 1.0
scala> println("Area under ROC = " + auROC)
Area under ROC = 1.0
```
其中, `SVMWithSGD.train()` 方法默认的通过把正则化参数设为1来执行来范数。如果我们想配置这个算法,可以通过创建一个新的 `SVMWithSGD`对象然后调用他的setter方法来进行重新配置。下面这个例子,我们构建了一个正则化参数为0.1的L1正则化SVM方法 ,然后迭代这个训练算法2000次。
```scala
import org.apache.spark.mllib.optimization.L1Updater
scala> val svmAlg = new SVMWithSGD()
svmAlg: org.apache.spark.mllib.classification.SVMWithSGD = org.apache.spark.mlli
b.classification.SVMWithSGD@475774a9
scala> svmAlg.optimizer.
| setNumIterations(2000).
| setRegParam(0.1).
| setUpdater(new L1Updater)
res3: svmAlg.optimizer.type = org.apache.spark.mllib.optimization.GradientDescen
t@62f740b7
scala> val modelL1 = svmAlg.run(training)
modelL1: org.apache.spark.mllib.classification.SVMModel = org.apache.spark.mllib
.classification.SVMModel: intercept = 0.0, numFeatures = 4, numClasses = 2, thre
shold = 0.0
```
自动标签 :
spark.mllib
支持
向量
数据
分类
模型
支持向量机
训练
线性
预测
进行
分类面
数据集
方法
学习