给定一个数据集,数据分析师一般会先观察一下数据集的基本情况,称之为汇总统计或者概要性统计。一般的概要性统计用于概括一系列观测值,包括位置或集中趋势(比如算术平均值、中位数、众数和四分位均值),展型(比如四分位间距、绝对偏差和绝对距离偏差、各阶矩等),统计离差,分布的形状,依赖性等。除此之外,spark.mllib库也提供了一些其他的基本的统计分析工具,包括相关性、分层抽样、假设检验,随机数生成等。在本章,我们将从以下几个方面进行介绍:
- 概括统计 summary statistics
- 相关性 correlations
- 分层抽样 Stratified sampling
- 假设检验 hypothesis testing
- 随机数生成 random data generation
- 核密度估计 Kernel density estimation
一、Iris数据集
Iris数据集也称鸢尾花卉数据集,是一类多重变量分析的数据集,是常用的分类实验数据集,由Fisher于1936收集整理。数据集包含150个数据集,分为3类,每类50个数据,每个数据包含4个属性。可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。大家可以到这个链接下载该数据集:https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data。 其基本数据的样子是:
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
4.7,3.2,1.3,0.2,Iris-setosa
4.6,3.1,1.5,0.2,Iris-setosa
5.0,3.6,1.4,0.2,Iris-setosa
5.4,3.9,1.7,0.4,Iris-setosa
4.6,3.4,1.4,0.3,Iris-setosa
5.0,3.4,1.5,0.2,Iris-setosa
4.4,2.9,1.4,0.2,Iris-setosa
... ...
二、摘要统计 Summary statistics
对于RDD[Vector]类型的变量,Spark MLlib提供了一种叫colStats()的统计方法,调用该方法会返回一个类型为MultivariateStatisticalSummary的实例。通过这个实例看,我们可以获得每一列的最大值,最小值,均值、方差、总数等。具体操作如下所示:
首先,我们导入必要的包:
import org.apache.spark.mllib.linalg.Vector
import org.apache.spark.mllib.stat.{MultivariateStatisticalSummary, Statistics}
接下来读取要分析的数据,把数据转变成RDD[Vector]类型:
scala> val observations=sc.textFile("G:/spark/iris.data").map(_.split(",")).map(p => Vectors.dense(p(0).toDouble, p(1).toDouble, p(2).toDouble, p(3).toDouble))
observations: org.apache.spark.rdd.RDD[org.apache.spark.mllib.linalg.Vector] = MapPartitionsRDD[3] at map at :32
上面我们就把莺尾花的四个属性,即萼片长度,萼片宽度,花瓣长度和花瓣宽度存储在observations中,类型为RDD[Vector]。
然后,我们调用colStats()方法,得到一个MultivariateStatisticalSummary类型的变量:
scala> val summary: MultivariateStatisticalSummary = Statistics.colStats(observations)
summary: org.apache.spark.mllib.stat.MultivariateStatisticalSummary = org.apache.spark.mllib.stat.MultivariateOnlineSummarizer@52137879
最后,依次调用统计方法,得到相应统计结果:
scala> println(summary.count)
150
scala> println(summary.mean)
[5.843333333333332,3.0540000000000003,3.7586666666666666,1.1986666666666668]
scala> println(summary.variance)
[0.685693512304251,0.18800402684563744,3.113179418344516,0.5824143176733783]
scala> println(summary.max)
[7.9,4.4,6.9,2.5]
scala> println(summary.min)
[4.3,2.0,1.0,0.1]
scala> println(summary.normL1)
[876.4999999999998,458.1000000000001,563.8000000000002,179.79999999999995]
scala> println(summary.normL2)
[72.27620631992245,37.77631533117014,50.82322303829225,17.38677658451963]
scala> println(summary.numNonzeros)
[150.0,150.0,150.0,150.0]
其中,主要方法的含义与返回值类型如下:
| 方法名 | 方法含义 | 返回值类型 |
|---|---|---|
| count | 列的大小 | long |
| mean | 每列的均值 | vector |
| variance | 每列的方差 | vector |
| max | 每列的最大值 | vector |
| min | 每列的最小值 | vector |
| normL1 | 每列的L1范数 | vector |
| normL2 | 每列的L2范数 | vector |
| numNonzeros | 每列非零向量的个数 | vector |
三、相关性Correlations
Correlations,相关度量,目前Spark支持两种相关性系数:皮尔逊相关系数(pearson)和斯皮尔曼等级相关系数(spearman)。相关系数是用以反映变量之间相关关系密切程度的统计指标。简单的来说就是相关系数绝对值越大(值越接近1或者-1),当取值为0表示不相关,取值为(0~-1]表示负相关,取值为(0, 1]表示正相关。
Pearson相关系数表达的是两个数值变量的线性相关性, 它一般适用于正态分布。其取值范围是[-1, 1], 当取值为0表示不相关,取值为[-1~0)表示负相关,取值为(0, 1]表示正相关。
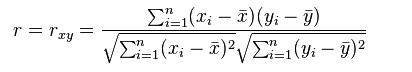
Spearman相关系数也用来表达两个变量的相关性,但是它没有Pearson相关系数对变量的分布要求那么严格,另外Spearman相关系数可以更好地用于测度变量的排序关系。其计算公式为:
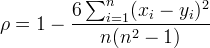
根据输入类型的不同,输出的结果也产生相应的变化。如果输入的是两个RDD[Double],则输出的是一个double类型的结果;如果输入的是一个RDD[Vector],则对应的输出的是一个相关系数矩阵。具体操作如下所示:
首先,我们导入必要的包:
import org.apache.spark.SparkContext
import org.apache.spark.mllib.linalg._
import org.apache.spark.mllib.stat.Statistics
接下来我们先从数据集中获取两个series,这两个series要求必须数量相同,这里我们取莺尾花的前两个属性:
scala> val seriesX = sc.textFile("G:/spark/iris.data").map(_.split(",")).map(p => p(0).toDouble)
seriesX: org.apache.spark.rdd.RDD[Double] = MapPartitionsRDD[8] at map at :35
scala> val seriesY = sc.textFile("G:/spark/iris.data").map(_.split(",")).map(p => p(1).toDouble)
seriesY: org.apache.spark.rdd.RDD[Double] = MapPartitionsRDD[12] at map at :35
然后,我们调用Statistics包中的corr()函数来获取相关性,这里用的是"pearson",当然根据不同需要也可以选择"spearman":
scala> val correlation: Double = Statistics.corr(seriesX, seriesY, "pearson")
correlation: Double = -0.10936924995064437
scala> print(correlation)
-0.10936924995064437
说明数据集的前两列,即花萼长度和花萼宽度具有微小的负相关性。
上面介绍了求两个series的相关性,接下来介绍一下如何求相关系数矩阵。方法是类似的,首先还是先从数据集中获取一个RDD[Vector],为了进行对照,我们同样选择前两个属性:
scala> val data = sc.textFile("G:/spark/iris.data").map(_.split(",")).map(p
=> Vectors.dense(p(0).toDouble, p(1).toDouble))
data: org.apache.spark.rdd.RDD[org.apache.spark.mllib.linalg.Vector] = MapPartit
ionsRDD[20] at map at :35
然后,我们调用Statistics包中的corr()函数,这里也同样可以选择"pearson"或者"spearman",得到相关系数矩阵:
scala> val correlMatrix1: Matrix = Statistics.corr(data, "pearson")
correlMatrix1: org.apache.spark.mllib.linalg.Matrix =
1.0 -0.10936924995064437
-0.10936924995064437 1.0
scala> print(correlMatrix1)
1.0 -0.10936924995064437
-0.10936924995064437 1.0
相关矩阵也叫相关系数矩阵,是由矩阵各列间的相关系数构成的。也就是说,相关矩阵第i行第j列的元素是原矩阵第i列和第j列的相关系数。可以看到,输入两个RDD[Double]或一个RDD[Vector],求相关性得到结果是一致的。
四、分层抽样 Stratified sampling
分层取样(Stratified sampling)顾名思义,就是将数据根据不同的特征分成不同的组,然后按特定条件从不同的组中获取样本,并重新组成新的数组。分层取样算法是直接集成到键值对类型 RDD[(K, V)] 的 sampleByKey 和 sampleByKeyExact 方法,无需通过额外的 spark.mllib 库来支持。
(一)sampleByKey 方法
sampleByKey 方法需要作用于一个键值对数组,其中 key 用于分类,value可以是任意数。然后通过 fractions 参数来定义分类条件和采样几率。fractions 参数被定义成一个 Map[K, Double] 类型,Key是键值的分层条件,Double 是该满足条件的 Key 条件的采样比例,1.0 代表 100%。
首先,导入必要的包:
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.rdd.PairRDDFunctions
接下来,这里为了方便观察,没有从iris数据集中取数据,而是重新创建了一组数据,分成 “female” 和 “male” 两类:
scala> val data = sc.makeRDD(Array(
| ("female","Lily"),
| ("female","Lucy"),
| ("female","Emily"),
| ("female","Kate"),
| ("female","Alice"),
| ("male","Tom"),
| ("male","Roy"),
| ("male","David"),
| ("male","Frank"),
| ("male","Jack")))
data: org.apache.spark.rdd.RDD[(String, String)] = ParallelCollectionRDD[0] at makeRDD at :26
然后,我们通过 fractions 参数来定义分类条件和采样几率:
scala> val fractions : Map[String, Double]= Map("female"->0.6,"male"->0.4)
fractions: Map[String,Double] = Map(female -> 0.6, male -> 0.4)
这里,设置采取60%的female和40%的male,因为数据中female和male各有5个样本,所以理想中的抽样结果应该是有3个female和2个male。接下来用sampleByKey进行抽样:
scala> val approxSample = data.sampleByKey(withReplacement = false, fractions, 1)
approxSample: org.apache.spark.rdd.RDD[(String, String)] = MapPartitionsRDD[1] at sampleByKey at :30
scala> approxSample.collect().
| foreach {
| println
| }
(female,Lily)
(female,Lucy)
(female,Emily)
(female,Kate)
(female,Alice)
(male,Tom)
从上面可以看到,本应该抽取3个female和2个male,但结果抽取了5个female和1个male,结果并不够准确,不过在样本数量足够大且要求一定效率的情况下,用sampleByKey进行抽样还是可行的。
(二)sampleByKeyExact 方法
sampleByKey 和 sampleByKeyExact 的区别在于 sampleByKey 每次都通过给定的概率以一种类似于掷硬币的方式来决定这个观察值是否被放入样本,因此一遍就可以过滤完所有数据,最后得到一个近似大小的样本,但往往不够准确。而 sampleByKeyExtra 会对全量数据做采样计算。对于每个类别,其都会产生 (fk⋅nk)个样本,其中fk是键为k的样本类别采样的比例;nk是键k所拥有的样本数。 sampleByKeyExtra 采样的结果会更准确,有99.99%的置信度,但耗费的计算资源也更多。
接下来是sampleByKeyExact的例子:
scala> val exactSample = data.sampleByKeyExact(withReplacement = false, fractions, 1)
exactSample: org.apache.spark.rdd.RDD[(String, String)] = MapPartitionsRDD[3] at sampleByKeyExact at :30
scala> exactSample.collect().
| foreach {
| println
| }
(female,Lily)
(female,Kate)
(female,Alice)
(male,Tom)
(male,Roy)
从实验结果可以看出,所得结果和预想一致,但当样本数量比较大时,可能会耗时较久。其中,sampleByKeyExact抽样方法中所涉及到的参数解释如下:
| 参数 | 含义 |
|---|---|
| withReplacement | 每次抽样是否有放回 |
| fractions | 控制不同key的抽样率 |
| seed | 随机数种子 |
自动标签 : spark.mllib 统计 工具 相关系数 数据 数据集 可以 相关性 结果 相关 类型 方法 相关系数矩阵 抽样
更多 [ 技术 ] 文章